
Pdf-technologie heeft de afgelopen decennia de digitalisering van archieven enorm verbeterd. Wat ooit een uitdagende taak was op het gebied van gegevensbehoud en de mogelijkheid om documenten op te slaan zodat ze gemakkelijk kunnen worden teruggehaald, is nu heel gewoon geworden. Een van de belangrijkste factoren die deze verandering hebben veroorzaakt, is OCR of in het Nederlands: optische tekenherkenning. Laten we eens kijken waarom OCR zo'n belangrijke rol speelt bij de digitalisering van archieven, hoe het als proces wordt toegepast en hoe de nauwkeurigheid van OCR via verschillende methodes kan worden verbeterd.
Deel 1. Toepassing van OCR bij archiefdigitalisering
OCR is in feite het proces van het herkennen, extraheren en inbedden van de tekstinhoud van een op afbeeldingen gebaseerd digitaal of fysiek document in de bestaande afbeeldingslaag. Deze dubbellaagse technologie wordt ondersteund door pdf, waardoor het een ideaal medium is voor archiefdigitalisering. Er zijn nog andere overwegingen die pdf tot het perfecte middel maken om documentarchieven te digitaliseren.
1. Innoveren op basis van traditionele catalogiserings- en indexeringsmethodologieën
Catalogiseren en indexeren gaan vaak samen, maar zijn twee totaal verschillende processen. Catalogiseren is het organiseren van onderwerpen of inhoudsitems, en indexeren houdt verband met het ophalen van informatie. Beide zijn vereist bij het archiveren van documenten, audiovisuele media, kranten, tijdschriften, wetenschappelijke bladen en andere soorten inhoud. Catalogiseren vertelt je wat er beschikbaar is, terwijl indexeren een manier biedt om de juiste informatie te vinden waarnaar je op zoek bent.
Door fysieke documenten of gescande bestanden naar pdf te converteren, kan zowel catalogiseren als indexeren tegelijkertijd plaatsvinden met behulp van OCR-technologie. De gedigitaliseerde inhoud kan bewerkbaar of doorzoekbaar worden gemaakt, waardoor archiefcatalogisering en -indexering eenvoudig mogelijk wordt. Daarom is OCR eigenlijk een nieuwe manier om documentarchieven te catalogiseren en te indexeren, waardoor het proces via computers toegankelijk wordt.
2. Realiseren van het daadwerkelijk ophalen van volledige tekst
Handmatige indexering is meestal gevoelig voor menselijke fouten, die kunnen variëren van 3% tot wel 30%, afhankelijk van de taak die moet worden uitgevoerd. Dit betekent dat op tekst gebaseerde documenten mogelijk niet correct worden geïndexeerd als het proces handmatig wordt uitgevoerd. Hetzelfde geldt ook voor catalogiseren, maar in mindere mate. Met behulp van OCR is conversie echter mogelijk met een nauwkeurigheid van 98% tot 99%. Dit maakt op zijn beurt het zoeken en ophalen van de volledige tekst mogelijk. Wanneer deze mogelijkheid gecombineerd wordt met metagegevens en indexeringselementen, ontstaat er een verbeterd catalogiserings- en indexeringssysteem.
3. Dubbellaagse pdf-technologie
Hoewel over het algemeen wordt aangenomen dat OCR een tekstlaag in de bestaande afbeelding insluit, wordt deze in werkelijkheid weergegeven als onzichtbare tekst in de pdf. Deze tekst kan nu echter geselecteerd worden en is dus doorzoekbaar. Bij het digitaliseringsproces van het archief zal de archivaris eerst controleren of de gedigitaliseerde tekstlaag consistent is met de tekst in de originele afbeelding. Deze kwaliteitsborgingsstap is van cruciaal belang voor de nauwkeurigheid van de weergegeven tekst. Dergelijke wijzigingen worden vervolgens opgeslagen in de OCR-kopie van het bestand, waardoor het gemakkelijker wordt om te zoeken met trefwoorden. Eventuele typefouten die tijdens deze kwaliteitscontrole worden weggelaten, zorgen ervoor dat het document ondoorzoekbaar wordt op dat specifieke trefwoord. Hier speelt de gelaagdheid een rol. Hiermee kan de archivaris visueel controleren of de tekens die door de OCR-motor worden herkend consistent zijn met de tekens in het originele, op afbeeldingen gebaseerde bestand.
4. Het gebruik van gearchiveerde bestanden uitbreiden
Het uitvoeren van OCR op een pdf-document levert een doorzoekbare laag op, maar het kan de tekst ook bewerkbaar maken. Voor het archiveren en terugvinden heeft een doorzoekbaar document echter de voorkeur, omdat de indexeringsinformatie kan helpen bij het retourneren van zoekresultaten in de volledige tekst. Hierdoor kunnen OCR-documenten in verschillende scenario's worden gebruikt, afhankelijk van of deze bewerkbaar of doorzoekbaar zijn. Het is bijvoorbeeld veel gemakkelijker om een stuk tekst in een afbeeldingsbestand te corrigeren met behulp van OCR dan om diezelfde tekst te corrigeren in een afbeeldingsbewerkingstool. OCR heeft veel van dergelijke gebruiksmogelijkheden die traditionele archiveringstechnieken niet kunnen evenaren.
Deel 2. Hoe je het OCR-herkenningspercentage kunt verbeteren
De nauwkeurigheid van een OCR-sessie is afhankelijk van verschillende softwarematige en handmatige overwegingen, en deze worden hieronder vermeld. Met al deze parameters kan OCR nauwkeuriger zijn, en ze kunnen tijdens de kwaliteitsborging worden gecontroleerd in de pre-OCR-fase of in de post-OCR-fase.
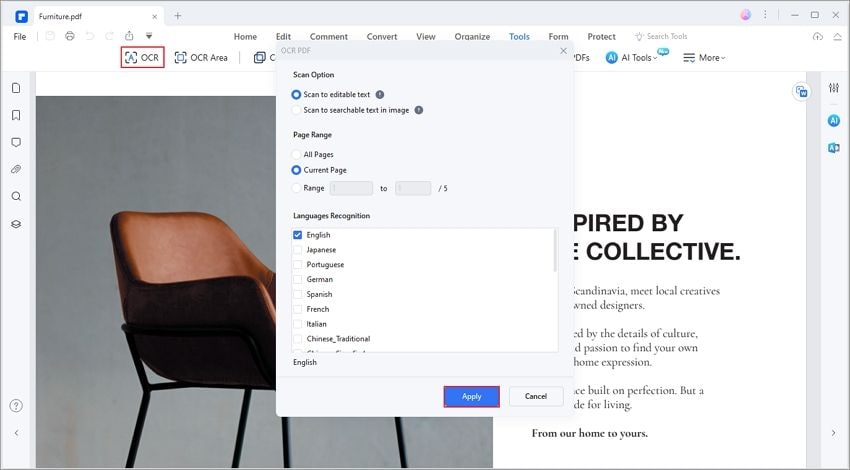
1. De juiste software gebruiken - PDFelement
De OCR-plug-in in PDFelement is zeer nauwkeurig en werkt met meerdere talen, zelfs tegelijkertijd. Ook biedt PDFelement conversie naar zowel doorzoekbare als bewerkbare versies van het originele pdf-bestand. Het kan tevens rechtstreeks een pdf maken met behulp van de invoer van een scanner, en niet-tekstbestandsformaten converteren naar bewerkbare/doorzoekbare pdf's.
2. De juiste scanparameters
Bij het scannen van documenten is het belangrijk om de juiste parameters in je scannerinstellingen in te stellen. Sommige ervan zullen al juist ingesteld zijn. De belangrijkste hiervan is oriëntatie. Zorg ervoor dat het document recht in de scanner wordt ingevoerd, omdat een scheve scan de OCR-nauwkeurigheid ernstig kan beïnvloeden.
3. Resolutie-instelling
De beste resolutie voor nauwkeurige OCR is 300 dpi of dots per inch. Deze hogere dichtheid zorgt voor een ‘strakkere’ scan, waardoor de OCR-motor kan werken met het dubbele aantal referentiepunten vergeleken met 150 dpi.
4. Kleurselectiemodus
Voor verkleurde of oude documenten is RGB de aanbevolen kleurmodus, zodat de scanner de inhoud van het fysieke document volledig kan vastleggen. Over het algemeen is scannen in grijswaardenmodus echter de beste optie voor de OCR-nauwkeurigheid. Hoewel je met de zwart-witmodus de afbeelding sneller kunt scannen, kan dit de kwaliteit van de tekstherkenning beïnvloeden.
5. Helderheids- en contrastaanpassingen
Voor de helderheid kunnen beide uitersten (te hoog of te laag) een negatieve invloed hebben op de OCR-kwaliteit en -nauwkeurigheid. Om die reden is 50% de aanbevolen helderheidsinstelling. Dit is echter ook afhankelijk van de scanner zelf, dus er kan eerst een fase van vallen en opstaan worden verwacht.
Wat het contrast betreft, heeft de hoogste instelling meestal de voorkeur, omdat OCR in essentie werkt door donkere en lichte gebieden te analyseren om individuele tekens te identificeren. Er worden vervolgens regels toegepast om deze resultaten te matchen met bekende tekens, tekst en cijfers. Als het contrast tussen het donkere gedeelte van de tekst hoog is ten opzichte van de omringende niet-tekstgedeelten, is OCR nauwkeuriger.
6. Beeldcorrectie en decontaminatie
Deze twee elementen hebben een grote invloed op de kwaliteit van OCR-scannen. Beeldcorrectie omvat aspecten zoals het verhogen van de resolutie, het toepassen van kleurcorrecties en het uitproberen van verschillende contrastinstellingen, en decontaminatie is het verwijderen van niet-tekstuele tekens, zoals pictogrammen, niet-tekstuele afbeeldingen, ongebruikelijke tekens, enzovoort. Beide zijn belangrijk omdat ze de OCR-motor in staat stellen het document nauwkeuriger te ‘lezen’.
7. Zorgvuldige handmatige proeflezing
Afhankelijk van hoe nauwkeurig je het eindresultaat wilt hebben, kan handmatig proeflezen wel of niet nodig zijn. Als nauwkeurigheid voorop staat, dan is dit een onmisbare stap in het archiefdigitaliseringsproces. Het gaat in feite om menselijke verificatie om ervoor te zorgen dat de gescande tekens correct worden herkend in de context van het gescande beeld. Het is een vervelend en moeizaam proces, maar in veel gevallen essentieel.
PDFelement - De beste OCR-software voor archiefdigitalisering
PDFelement biedt een zeer nauwkeurige OCR-motor, maar brengt ook verschillende andere voordelen met zich mee als het gaat om archiefdigitalisering. Hier zijn enkele functies die het de perfecte software maken voor OCR-pdf's en -scans.
- Volledige bewerkingsmogelijkheden - Eenmaal geconverteerd naar een bewerkbare pdf, kan een document gemakkelijk worden aangepast met behulp van de bewerkingstools voor afbeeldingen, tekst, tabellen, grafieken, voetteksten/kopteksten, watermerken, hyperlinks en andere inhoud.
- Meertalige OCR - Als je een document hebt waarin meer dan één taal aanwezig is, kun je met vertrouwen PDFelement gebruiken voor het OCR-proces. Het ondersteunt meer dan 20 talen, wat de algehele nauwkeurigheid van tekstherkenning helpt vergroten.
- Batchproces - OCR kan worden uitgevoerd op een batch documenten, waardoor tijd wordt bespaard in het digitale archiveringsproces.
- Annotaties - Geconverteerde bestanden kunnen worden geannoteerd met notities, markeringen en andere inhoud, wat het indexeringsproces vereenvoudigt. De annotatielijst en de indeling met tabbladen van PDFelement maken het eenvoudig om naar teksten te verwijzen bij het onderzoeken van een bepaald onderwerp met behulp van OCR-bestanden.
- E-ondertekening en beveiliging - Bestanden kunnen digitaal of elektronisch worden ondertekend en worden beschermd tegen ongeoorloofd bekijken of bewerken met behulp van op wachtwoorden gebaseerde codering. Dit helpt de authenticiteit van een document te valideren en voorkomt dat er wijzigingen worden aangebracht. Redactie is nog een andere handige functie die je kunt gebruiken om te voorkomen dat gevoelige informatie doorzoekbaar is.
- Bestanden- en pagina-organisatie - Simpele manieren om bestanden te splitsen en samen te voegen, pdf-portfolio's te maken, documenten te vergelijken na OCR, pagina's toe te voegen/verwijderen/herordenen, pagina's te extraheren, enz.
- Bestandsgrootte verkleinen - De PDF Optimize-functie in PDFelement helpt archivarissen grote hoeveelheden informatie op een zeer efficiënte manier op te slaan.
Om deze en andere redenen wordt PDFelement beschouwd als een van de beste pdf-bewerkers voor OCR en aanverwante taken. De software is ook een van de meest betaalbare premium pdf-tools voor zowel kleine bedrijven als organisaties op ondernemingsniveau, waardoor het een haalbare oplossing is voor bedrijven, onderwijsinstellingen en allerlei soorten entiteiten in de overheids-, publieke en private sector.

Carina Lange
staff Editor