Wondershare PDF OCR Converter Nieuwe release
Zet gescande bestanden om naar bewerkbare
en doorzoekbare PDF's
Herken nauwkeurig tekst op afbeeldingen of gescande PDF's en bewerk gescande bestanden met één klik.
OCR-engine in de sector.
nauwkeurigheid.
talen.


Wat is OCR?
OCR staat voor Optical Character Recognition (Optische Tekenherkenning). Het is een wijdverspreide technologie die het mogelijk maakt om tekst in afbeeldingen, zoals gescande documenten en foto's, optisch te herkennen.
Met ingebouwde Optical Character Recognition (OCR) technologie beschikt PDFelement over een handige OCR-converter die tekst kan herkennen uit PDF-documenten. Het behoudt en reproduceert de documentopmaak en opmaak-elementen – kopteksten, voetteksten, afbeeldingen, voetnoten, paginanummering en bijschriften.
Met één klik gescande PDF bewerkbaar maken en
doorzoekbaar in HD-kwaliteit.
Bewerk tekst in gescande PDF-documenten.
Met de OCR-functie kun je gescande PDF's en op afbeeldingen gebaseerde PDF's even eenvoudig bewerken als een Word-document. Nieuw toegevoegde tekst kan synchroniseren met de bestaande lettertypen in je gescande PDF of afbeelding.
Bewerk tekst in gescande PDF-documenten.

Zet afbeeldingen om naar bewerkbaar Microsoft Office-formaat.
Zet gescande PDF- en afbeeldings-PDF's om naar verschillende formaten met bewerkbare, selecteerbare en doorzoekbare inhoud, zoals Microsoft Office-formaten, Pages of een gewoon tekstbestand (TXT-bestand).
Zet afbeeldingen om naar bewerkbaar Microsoft Office-formaat.

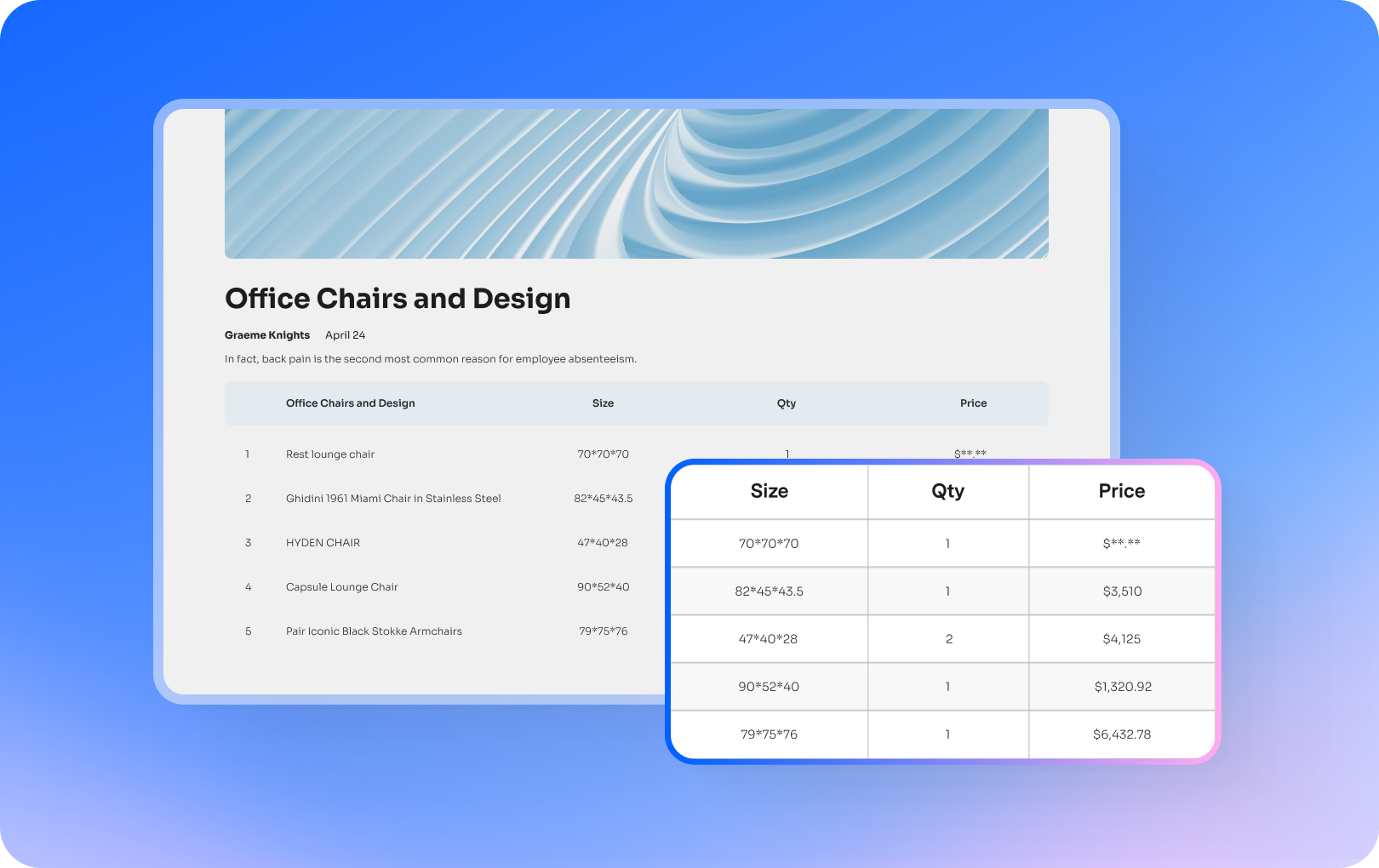
Gegevens extraheren uit gescande PDF.
Handmatige gegevensinvoer behoort tot het verleden. PDFelement stelt je in staat om gegevens te extraheren uit geselecteerde gebieden van gescande PDF- en afbeeldings-PDF's, of om gegevens uit formuliervelden in PDF te halen na het uitvoeren van OCR.
Gegevens extraheren uit gescande PDF.
OCR PDF-bestanden in bulk.
Zet eenvoudig meerdere gescande of afbeeldings-PDF's om naar bewerkbare en doorzoekbare PDF-bestanden, zonder gedoe. Los je probleem met massale documentverwerking op.
OCR PDF-bestanden in bulk.

Selecteer en OCR een gebied van een PDF.
Om een specifiek gedeelte van een PDF-document met OCR te verwerken op basis van positie of inhoud, zet je de pagina om naar een afbeelding, geef je het gewenste gebied aan (ROI), en start je vervolgens de OCR-engine.
Selecteer en OCR een gebied van een PDF.

Veilige, conforme en professionele PDF-software – bekroond.
PDFelement heeft de G2 Best Software Awards 2024 – Top 50 Office Products gewonnen, ontving de ISO 27001 – Informatiebeveiligingscertificering, en is een erkend lid van de PDF Association.



Beste gratis OCR-software voor Windows/Mac/iOS:










Wondershare PDF-documentenbeheer
VS. PDF Organizer online.

Is Wondershare OCR PDF to Word Software beter dan OCR Online?
ondersteunde formaten
PUB en scannerbestanden.
Snelle verwerking
Geen kwaliteitsverlies
Offline werken
Beveiliging en privacy:

Zijn online OCR-converters beter?
gratis te gebruiken
crossplatform
geen installatie
eenvoudig in gebruik
Geschikt voor kleine bestanden
Een slimme OCR-lezer voor iedereen.
Hoe kun je een gescand PDF-bestand omzetten naar een bewerkbare PDF?



























IT-dienst
Gebruik de OCR PDF-functie om PDF-scans om te zetten naar doorzoekbare bestanden, en sla op als Office-bewerkbare formaten om verschillende soorten verzamelde data te beheren en te categoriseren.
-- Preston, Programmeur
Creatieve dienst
Converteer gedownloade webpagina's in batch met OCR om ze doorzoekbaar te maken en gegevens te extraheren.
-- Edna, Kunstenaar
Onderwijs
Lees academische tijdschriften, waarvan vele uit afbeeldingen bestaan, gebruik de OCR-functie van PDFelement om zinnen te markeren en zoekwoorden in artikelen te vinden om de onderzoeksefficiëntie te verhogen.
-- Marty, Onderzoeker