
Stel je voor dat je met honderden gescande pagina's of op afbeeldingen gebaseerde PDF's werkt en je realiseert dat je er geen tekst in kunt kopiëren of doorzoeken. Het is frustrerend als je gewoon snel informatie hoeft te extraheren of een geautomatiseerde workflow hoeft te bouwen. DeepSeek verandert dat door gescande documenten om te zetten in machinaal leesbare tekst met behulp van zijn geavanceerde optische tekenherkenningstechnologie.
Of u nu lange PDF's wilt verwerken, verbinding wilt maken via de DeepSeek OCR API of de GitHub-bronnen wilt verkennen, deze gids leidt u door alles. U vindt ook een eenvoudiger, codeloos OCR-alternatief voor directe PDF-opruiming en meertalige tekstextractie.
In dit artikel
- Snel antwoord
- Wat Is DeepSeek OCR?
- DeepSeek OCR API — Hoe noem je het
- DeepSeek OCR op GitHub — Kloon en voer lokaal uit
- DeepSeek OCR gebruiken voor PDF's
- Ollama + DeepSeek OCR (lokaal-eerste idee)
- Een sneller pad voor alledaagse Teams: PDFelement (No-Code PDF OCR & Cleanup)
- DeepSeek OCR versus PDFelement versus Classic OCR — wanneer u wat moet gebruiken
- Stapsgewijze speelboeken (kopieerklaar)
- Bekende overwegingen (nauwkeurigheid, beveiliging, beschikbaarheid)
Deel 1. Snel antwoord
DeepSeek-OCR is open source software die "optische compressie" gebruikt om enorme documenten met ultralange context te verwerken. Het is het beste voor ontwikkelaars die grootschalige extractie nodig hebben en is beschikbaar op GitHub met volledige API-documenten online. Voor de meeste teams die meertalige OCR met een eenvoudige GUI nodig hebben, zijn de OCR-en Enhance Scan-functies van PDFelement praktischer. Kies DeepSeek voor token-efficiëntie en kies PDFelement voor dagelijkse PDF-tekstextractie en-opruiming via gebruiksvriendelijke tools.
Deel 2. Wat Is DeepSeek OCR?
Dit systeem transformeert documenten in compacte visuele tokens en maakt ultraefficiënte verwerking van lange context voor AI mogelijk. Het behoudt een complexe lay-outstructuur, verlaagt tokenkosten en voert analyse-ready tekst uit. Om taalmodellen te helpen langere documenten in één keer te verwerken, comprimeert het pagina's in een visuele presentatie. Ondersteunt meertalige en gemengde documenten in onderzoeks-, ondernemings-en ontwikkelaarsworkflows. Laten we eens kijken naar enkele belangrijke mogelijkheden en voordelen die deze tool biedt.

- Optische compressie-engine: converteert pagina's naar compacte visuele tokens, zodat taalmodellen veel langere contexten verwerken.
- 10× Token Reduction: Verlaagt het aantal tokens met ongeveer tien keer en behoudt tegelijkertijd sterke herkenning in verschillende documentlay-outs.
- Verwerking met hoge doorvoer: levert hoge doorvoer op workloads met meerdere pagina's met behulp van geoptimaliseerde tegel-, batch-en cachestrategieën.
- Dynamische modi/resolutie: past resolutie en weergaven aan voor wetenschappelijke PDF's, facturen, tabellen, grafieken en diagramzware bestanden.
- Gestructureerde uitvoer: Produceert gestructureerde Markdown of JSON om tabellen, lijsten, grafieken en de algehele documenthiërarchie te behouden.
U kunt het volledige onderzoeksoverzicht en codevoorbeelden bekijken in DeepSeek's officiëleGitHub-opslagplaatsenTechnische papieren.
Deel 3. DeepSeek OCR API — Hoe noem je het
Met de DeepSeek OCR API kunnen ontwikkelaars geavanceerde documentverwerking integreren in hun workflows. Het is gemakkelijk toegankelijk voor ontwikkelaars die bekend zijn met OpenAI SDK's, zonder dat ze een volledig nieuw API-formaat hoeven te begrijpen, dankzij de OpenAI-compatibiliteit. Gebruikers kunnen gescande pagina's, afbeeldingen of PDF's verzenden en gestructureerde tekstuitvoer ontvangen met deze API. De resultaten zijn klaar voor AI-workflows, kennisbases of onderzoekspijplijnen.
API-formaat en aanvraagstructuur
De API gebruikt een standaard HTTP-aanvraagstructuur die compatibel is met OpenAI-stijl SDK's. Een typisch verzoek omvat:
- Eindpunt-URL: het API-eindpunt waar u verzoeken stuurt om documenten te verwerken, bijv.https://api.deepseek.com/v1/ocr.
- Headers: vermeld uw dragertoken en alle vereiste authenticatiegegevens voor toegang.
- Invoerbestand: Geef een geüploade afbeelding, een PDF-pagina of een openbare URL voor OCR-verwerking.
- Optionele Parameters: Geef taal, lay-outmodus, resolutie of andere voorkeuren op voor betere resultaten.
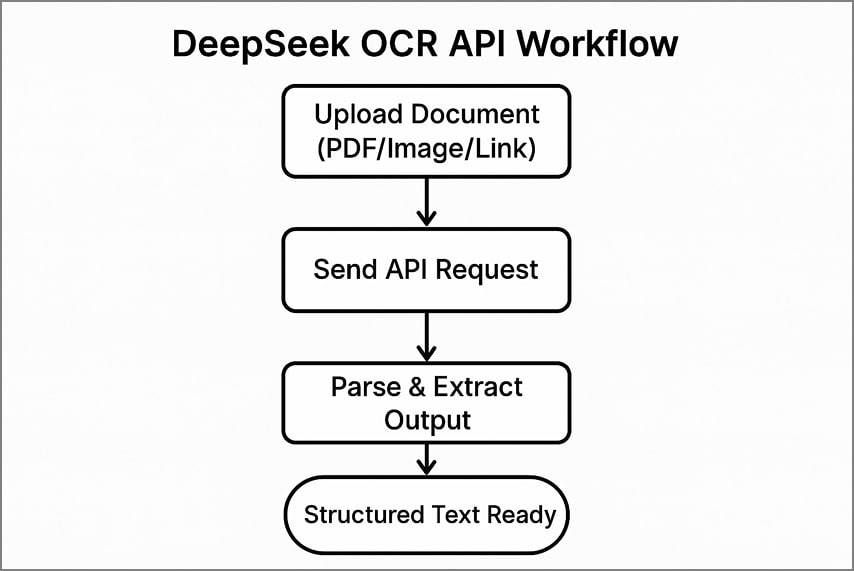
Typische API-workflow
Het gebruik van de DeepSeek OCR voor API omvat 3 duidelijke stappen om documenten te verwerken en gestructureerde tekst te extraheren.
- Upload uw document naar de API door een bestand, een PDF-pagina of een openbare link te sturen.
- Stuur de API-oproep met uw authenticatieheders en gekozen opties voor verwerking.
- Parseer de geretourneerde JSON of tekst om herkende inhoud, lay-outdetails en visuele tokens nauwkeurig te extraheren.
Tarieflimieten, beschikbaarheid en betrouwbaarheid
Hoewel de API krachtig is, moeten ontwikkelaars zich bewust zijn van enkele operationele overwegingen:
- Servicebeschikbaarheid: de API heeft af en toe schommelingen in uptime laten zien, dus plan voor mogelijke downtime of langzamere reactietijden in de productie.
- Snelheidslimieten: Wanneer u te maken hebt met grootschalige verwerking, kunt u een limiet bereiken op de dagelijkse of per minuut snelheid, waardoor u herpogingen gebruikt als een manier om de continuïteit te behouden.
- Foutafhandeling: Controleer altijd antwoorden op fouten en verwerk uitzonderingen sierlijk om mislukte workflows in de productie te voorkomen.

Deel 4. DeepSeek OCR op GitHub — Kloon en voer lokaal uit
We zullen onderzoeken hoe u DeepSeek OCR GitHub lokaal kunt installeren door de Python-omgeving in te stellen na het klonen van de repository.
Toegang tot de Repository
DeepSeek OCR is beschikbaar als een open-sourceproject op GitHub dat ontwikkelaars volledige toegang biedt tot de architectuur en scripts. De repository bevat omgevingsconfiguratiebestanden en documentatie voor implementatie of aanpassing. Het wordt gedistribueerd onder een permissieve licentie en ondersteunt zowel onderzoek als productiegebruik. Het project heeft een actieve community die regelmatig bijdraagt aan bugfixes en workflowverbeteringen voor lokale implementatie.

Lokale opstelling (stapsgewijze opdrachten)
Om DeepSeek OCR lokaal te installeren, kloon je gewoon de repository en bereid je Python-installatie voor:
"git-kloon https: / /github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
python-m venv venv
bron venv/bin/activate#Windows: venv\Scripts\activate
pip installatie-r vereisten.txt "
De tool is compatibel met Python versie 3.9 of latere releases. Modelgewichten kunnen automatisch worden gedownload bij het eerste gebruik of handmatig via links in het README-bestand.
GPU-vereisten en prestatienotities
DeepSeek OCR kan op een CPU draaien, hoewel een CUDA-compatibele GPU ten zeerste wordt aanbevolen voor het verwerken van OCR-workloads met een groot volume. In interne vergelijkingen is er de mogelijkheid van 5-10 keer snellere doorvoer op de PDF's met meerdere pagina's of ingewikkelde documentlay-outs met behulp van GPU-versnelling. Voor optimale prestaties zorgt u ervoor dat uw NVIDIA-drivers, CUDA-en PyTorch-versies zijn bijgewerkt.
Inferentie uitvoeren op PDF's
Nadat u de installatie hebt voltooid, test u een voorbeeld-PDF-bestand met de volgende opdracht:
"python infer.py- -input sample.pdf- -output output.json"
Elke pagina wordt weergegeven als een afbeelding en verwerkt via de VL2 Vision-pijplijn om tekst te detecteren en de lay-out te behouden. De gestructureerde JSON-of Markdown-uitvoer integreert in RAG-of Ollama-gebaseerde lokale LLM-workflows.
Deel 5. DeepSeek OCR gebruiken voor PDF's
Laten we eens kijken hoe ontwikkelaars DeepSeek vaak gebruikenOCR PDFMethoden om nauwkeurige tekst-en lay-outgegevens uit gescande of digitale documenten te extraheren.
Methoden die ontwikkelaars tegenwoordig gebruiken
Voor PDF's zijn er vandaag de dag twee praktische manieren waarop teams DeepSeek uitvoeren, afhankelijk van kwaliteit, kosten en latentieafwegingen.
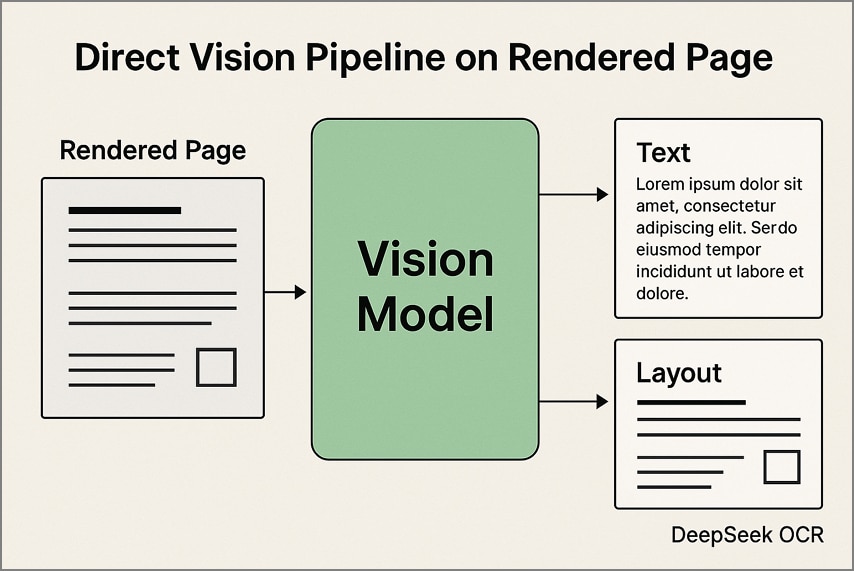
1. Direct Vision Pipeline op gerenderde pagina's
Bij deze aanpak wordt elke PDF-pagina omgezet In een afbeelding met een vaste resolutie voordat deze wordt verwerkt via DeepSeek OCR. Het model haalt zowel tekst-als lay-outdetails rechtstreeks uit de beelden, waarbij tabellen, kolommen en diagrammen in hun oorspronkelijke structuur blijven. Deze methode is vooral effectief voor gescande documenten en visueel complexe lay-outs.
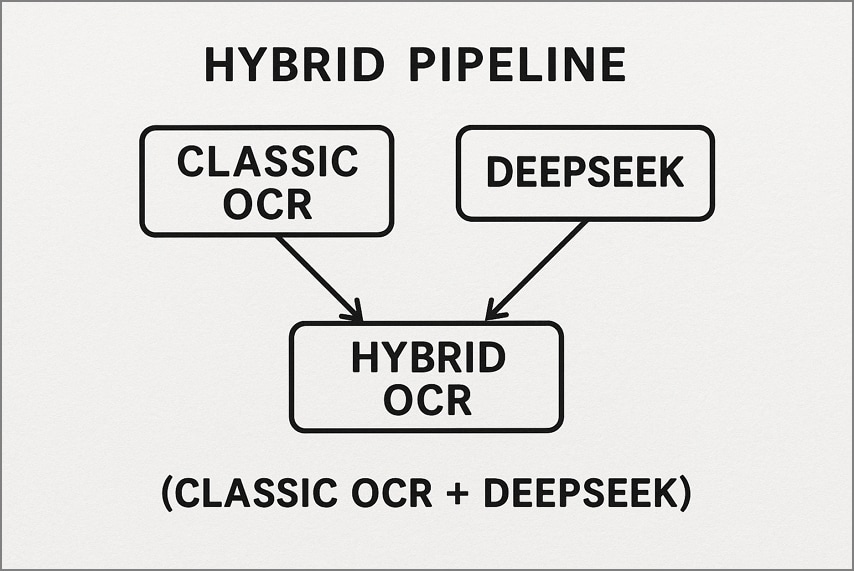
2. Hybride pijplijn (klassieke OCR + DeepSeek)
Hier verwerkt een traditionele OCR-tool zoals Tesseract eerst eenvoudige, hoogwaardige pagina's om snelle tekstuitvoer te produceren. Alleen de complexere of lawaaierigere pagina's worden doorgegeven aan DeepSeek OCR voor diepere lay-outreconstructie en semantisch begrip. Deze workflow verlaagt kosten en latentie en bereikt toch premium nauwkeurigheid op moeilijke documenten.
Randkoffers
Sommige documenten zijn moeilijker te verwerken dan standaard tekstpagina's, dus het is belangrijk om edge cases zorgvuldig te behandelen voor de beste OCR-nauwkeurigheid.
- Tijdschriften/kranten met meerdere kolommen: handhaaf de juiste kolomvolgorde af met post-OCR-lijngroepering, geef de voorkeur aan 300 DPI, tegel per kolom voor dichte pagina's.
- Stempels/Watermerken/Zegels: Masker of scheid overlays vóór OCR om valse tekst en verkeerde samenvoegingen te voorkomen, en voeg daarna opnieuw in.
- Scheef/rotatie: scheef eerst pagina's, detecteer de oriëntatie betrouwbaar en voer vervolgens OCR opnieuw uit op pagina's die zijn gedraaid.
- Scans met een lage DPI: Sample met ongeveer 1,5-2 keer en scherp, anders geef je de voorkeur aan opnieuw scannen bij een hogere DPI.
- Tabellen en formulieren: voer een tabeldetector of een headeruitlijningsstap uit om gesplitste cellen te repareren en valideer vervolgens totalen en sleutelvelden.
- Lettertypen/wiskunde/code: gebruik tegels met een hogere resolutie voor vergelijkingen, codeblokken en zeer kleine lettertypen en bewaar monospacing met codehekken.
Waarom nabewerking ertoe doet
Nabewerking is de eenvoudige opruiming na tekstextractie, zodat het resultaat correct leest. Het repareert gemengde kolommen, kapotte tabellen, rommelige koppen en stempels die per ongeluk als woorden worden gelezen. Als er iets mis lijkt, voer dan die pagina opnieuw uit met een hogere kwaliteit en controleer de totalen, data en ID's.
Deel 6. Ollama + DeepSeek OCR (lokaal-eerste idee)
Het is een lichtgewicht framework dat grote taalmodellen volledig op uw computer draait, met een eenvoudige lokale API en CLI. Met Ollama DeepSeek OCR kunt u gescande documenten en PDF's end-to-end op uw machine verwerken om cloudafhankelijkheden te voorkomen en de structuur in uitvoer zoals Markdown of JSON te behouden.
Gemeenschapsintegratie en voorbeelden
In dit gedeelte zullen we gemeenschapsprojecten onderzoeken die DeepSeek OCR combineren met Ollama-modellen voor lokale documentverwerking, extractie en analyse.
- Streamlit OCR Studio: Een Streamlit-dashboard neemt PDF's en afbeeldingen in en voert DeepSeek OCR uit voor gestructureerde tekst. Vervolgens beantwoordt dit model gebruikersvragen over de geëxtraheerde inhoud lokaal.
- Markdown Extractor + Ollama QA: Het hulpprogramma Image‑to‑Markdown wordt gebruikt om pagina-afbeeldingen om te zetten in clean Markdown voor downstream gebruik. Een Ollama-chatmodel vat documenten samen en haalt belangrijke velden uit PDF's en gescande afbeeldingen.
- Lokale analysator + Ollama API: een watch‑folder-service OCRs nieuwe bestanden met DeepSeek zodra ze aankomen. Het legt een lokaal Ollama-eindpunt bloot voor zoeken, vragen en antwoorden, redactie en workflowautomatisering.
Waarom lokale orkestratie helpt
Nadat we Ollama lokaal hebben uitgevoerd met DeepSeek OCR, laten we enkele belangrijke voordelen van deze opstelling onderzoeken.
- Bewaar documenten op het apparaat om te voldoen aan strikt gegevensbeleid en de blootstelling aan inbreuken tijdens audits te verminderen.
- Volledig draaien zonder internet in beveiligde laboratoria en netwerken met luchtgapen voor nalevingstests.
- Vermijd netwerkvertragingen, controleer batching en caching lokaal en stabiliseer de doorvoer voor grote PDF's.
Deel 7. Een sneller pad voor alledaagse Teams: PDFelement (No-Code PDF OCR & Cleanup)
Veel gebruikers zonder technische ervaring hebben vaak moeite om tekst uit gescande PDF's of op afbeeldingen gebaseerde documenten te extraheren. Naast DeepSeek OCR zoeken ze naar tools die eenvoudige OCR-verwerking, documentopruiming en snelle tekstextractie bieden zonder technische kennis. Dit is waarPDFelementkomt binnen, wat PDF-extractie vereenvoudigt met OCR zonder code en teams helpt documenten binnen enkele seconden om te zetten naar doorzoekbare formaten.
In tegenstelling tot andere tools kunnen gebruikers ook onderstreepen, een watermerk toevoegen, een achtergrond invoegen en met AI chatten over hun PDF's. PDFelement biedt u tot 20 GB opslagruimte om uw gegevens binnen deze tool op te slaan en rechtstreeks te delen via sociale mediaplatforms. Om het beoogde gebied bewerkbaar te maken, biedt het bovendien een "OCR-gebied"-optie voor het selecteren van specifieke delen van een document.
Ultieme gids voor No-Code PDF OCR in PDFelement
Nadat u meer hebt geleerd over de beste PDF OCR-tool voor niet-codeerders, volgt u deze stapsgewijze workflow om PDF's snel te verwerken als alternatief voor de DeepSeek OCR API:
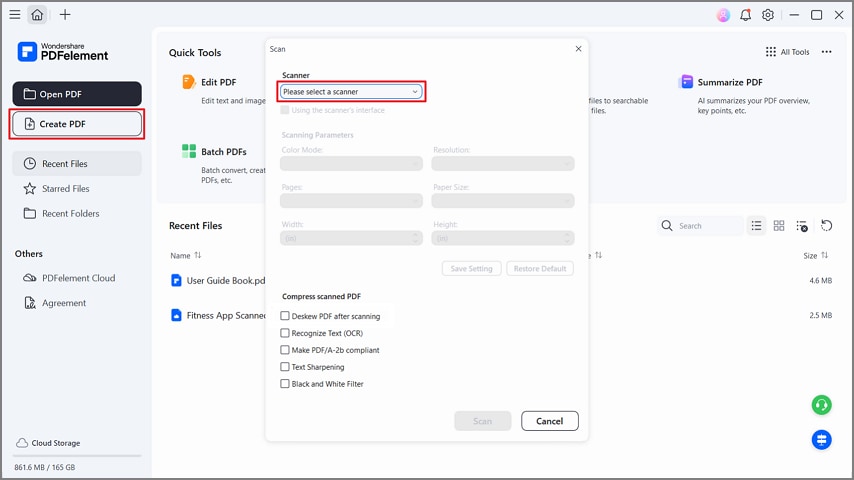
Stap 1PDF maken vanuit de Scanner
Zodra u de tool betreedt, drukt u op de knop "PDF maken" en selecteert u de optie "Van Scanner" in het vervolgkeuzemenu. Kies vervolgens uw scanner en vink de optie "Deskew PDF na het scannen" aan. Deze tool zet scans om in doorzoekbare of bewerkbare tekst met desktopondersteuning.
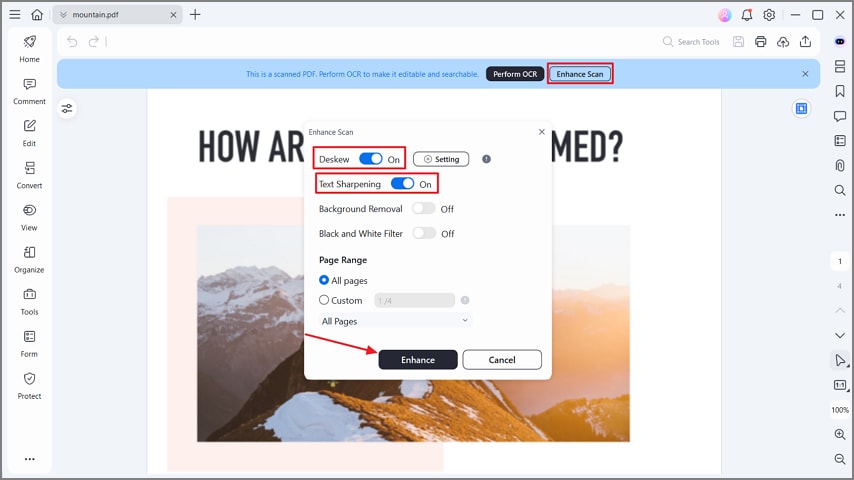
Stap 2Verbeter uw PDF
Nadat de gescande PDF is gemaakt, drukt u op de knop "Scan verbeteren". Schakel vervolgens de opties "Deskew" en "Text Sharpening" in en druk op de knop "Enhance" in het pop-upvenster. Het zal de tekst op PDF scherper maken om de nauwkeurigheid van OCR bij slechte scans te vergroten.
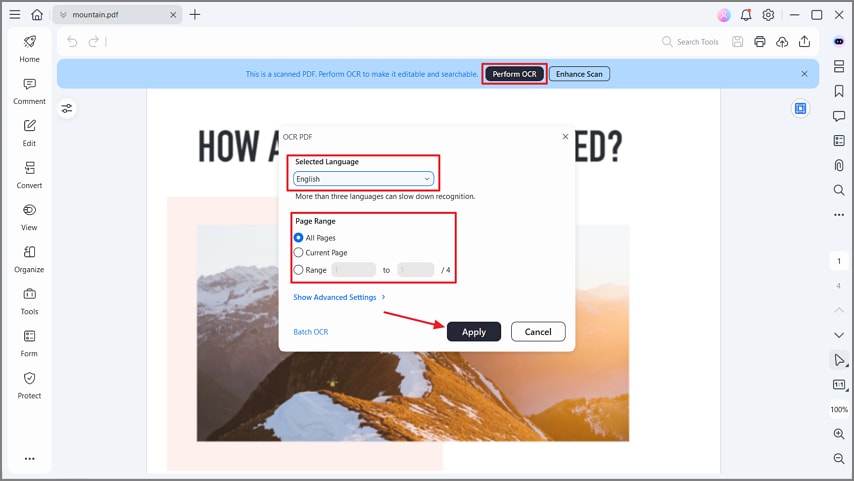
Stap 3Voer tekst OCR uit
Klik nu op de knop "OCR uitvoeren" en kies de juiste taal. Selecteer vervolgens een specifiek "Pagina-bereik" en druk op de knop "Toepassen" om het OCR-proces te starten. Hiermee wordt de tekst uit uw PDF geëxtraheerd om deze doorzoekbaar en bewerkbaar te maken voor beoordeling of export.
Stap 4Hardop lezen PDF
Zodra OCR is voltooid, drukt u op de optie "Bekijken" in het menu aan de linkerkant en drukt u op de optie "Hardop lezen" om naar uw PDF-tekst te luisteren. U kunt het luisteren op elk moment stoppen en pauzeren. Met deze functie kunt u uw PDF's proeflezen om eventuele fouten op te sporen.
Stap 5Annoteer en exporteer PDF
Klik op de knop "Reageer" en gebruik de tools in de werkbalk om tekst te markeren en opmerkingen toe te voegen aan de PDF. Druk ten slotte op de knop "Opslaan" om het PDF-bestand te exporteren. De annotatiefunctie helpt ook om stempels toe te voegen, vormen te tekenen, stickers te bevestigen en tekst te onderstrepen of door te strepen voor een betere documentbeoordeling.
Deel 8. DeepSeek OCR versus PDFelement versus Classic OCR — wanneer u wat moet gebruiken
Nadat we het beste DeepSeek OCR-alternatief hebben verkend, laten we eens kijken welke tools ideaal zijn voor verschillende use cases en documentworkflows.
Diepzoekende OCR
Het beste geschikt voor ontwikkelaarspilots die lange context redeneren, token-efficiënte RAG en lay-outbewuste markdown-of JSON-uitvoer vereisen. Verwacht installatie-en operatiewerk, inclusief GPU/VRAM-grootte, batching-of tegelkeuzes en af en toe edge-case-afstemming.
Wondershare PDFelement
Een solide keuze voor dagelijks documentwerk waarvoor meertalige OCR, visuele verbeteringsscan, annotaties en beoordeling nodig zijn. Exporten met één klik naar Word of Excel stroomlijnen overdrachten en teams vermijden codering of GPU-beheer.
Klassieke OCR-bibliotheken
Werkt beter bij hoge volume doorvoer wanneer lay-outs eenvoudig en consistent zijn in batches. Voeg lichtgewicht regels toe of een gerichte LLM-pas alleen op moeilijke pagina's om semantiek te injecteren zonder overal de kosten te betalen. Bekijk de onderstaande vergelijkingstabel om te begrijpen hoe elke tool past bij verschillende workflows en gebruikersbehoeften.
| gereedschap | Focus | opstelling | Lange Context | opruimen | meertalig | het beste voor |
| Diepzoekende OCR | Ontwikkelaarsworkflows, RAG | technisch | gematigd | Beperkt/Script | gematigd | Ontwikkelaars, prototyping, Onderzoek, RAG-pijpleidingen |
| PDFelement | Documentbewerking en beoordeling | Geen-code | hoog | Volledige GUI-tools | hoog | Bedrijfsteams, Operaties, compliance, Archivering |
| Klassieke OCR | Batchverwerking, eenvoudige documenten | technisch | Medium | op Script gebaseerd | gematigd | Batchjobs, backoffice, eenvoudige lay-outs |
Deel 9. Stapsgewijze speelboeken (kopieerklaar)
Nu u begrijpt hoe elke tool past bij verschillende workflows, laten we doorgaan naar snelle installatiegidsen. De volgende snelle playbooks laten zien hoe u DeepSeek OCR GitHub en andere opties gebruikt voor zowel ontwikkelaars als niet-ontwikkelaars.
Ontwikkelaars — Probeer DeepSeek OCR API in 10 minuten
- Stap 1. Genereer een API-sleutel uit "Account" of "API-sleutels" en stel "DEEPSEEK_API_KEY" in.
- Stap 2. Bereid bericht voor op "/v1/chat/completions" met model, systeemprompt en inhoudsschema.
- Stap 3. Render PDF-pagina's naar PNG met vaste DPI en voeg base64 toe in "Berichten".
- Stap 4. Vraag strikte JSON of Markdown aan en parseer vervolgens het veld "Inhoud" veilig.
- Stap 5. Valideer velden, verwerk herpogingen en blijf bij "Jobs" of "Storage".
ontwikkelaars — draaien vanaf GitHub (lokaal)
- Stap 1. "Kloon" de repo op een CUDA-ready machine en verifieer de versies van het driver of de toolkit.
- Stap 2. Maak venv, voer "pip install-r requirements.txt" uit, download "weights", stel "MODEL_PATH" in.
- Stap 3. Converteer PDF naar afbeeldingen met consistente DPI, voer "infer.py- -input pages- -output out- -format markdown" uit.
- Stap 4. Registreer "latentie", "VRAM" en "doorvoer" en vergelijk de nauwkeurigheid met een basislijn OCR.
Niet-ontwikkelaars — OCR schoonmaken voor PDF's in PDFelement
- Stap 1. Klik eerst op "PDF maken" en "Vanuit Scanner" om te scannen. Druk vervolgens op de knop "Enhance Scan" en schakel de opties "Deskew" en "Text Sharpening" in.
- Stap 2. Druk op "OCR uitvoeren", selecteer "Taal", kies "Bewerkbare tekst" of "Zoekbare tekst in afbeelding" en klik vervolgens op "Toepassen".
- Stap 3. Gebruik "AI Read" of "Lees hardop" om te bewijzen door te luisteren, corrigeer verkeerde lezingen die u tijdens het afspelen ziet.
- Stap 4. Druk nu op de knop "Reactie" op het linkerpaneel om "Hoogtepunten", "Opmerkingen" en "Stickers" toe te voegen om te beoordelen.
- Stap 5. Druk ten slotte op "Exporteren" om een doorzoekbare PDF op te slaan voor hand‑off.
Deel 10. Bekende overwegingen (nauwkeurigheid, beveiliging, beschikbaarheid)
Voordat u het volledig in de productie adopteert, is het belangrijk om een paar praktische factoren te bekijken die van invloed zijn op hoe de DeepSeek OCR API presteert bij gebruik in de echte wereld.
- Nauwkeurigheid: de resultaten variëren afhankelijk van de pagina-indeling en scankwaliteit, dus test eerst de prestaties op uw eigen corpus. Gebruik representatieve documenten, voeg tabellen en kolommen toe en volg fouten zoals splitsingen en samenvoegingen.
- Beveiliging en naleving: bekijk de gegevensverwerking, opslag en bewaring van leveranciers en vermijd het verzenden van gevoelige bestanden zonder beoordeling. Voeg redactie toe voordat u uploadt, beperk toegang en documenteer goedkeuringen om te voldoen aan audits en intern beleid.
- Beschikbaarheid en betrouwbaarheid: Diensten kunnen storingen of beperkingen ervaren, dus voeg lokaal herpogingen, backoffs en veerkrachtige backups toe. Bewaak foutpercentages en latentie, waarschuw voor storingen en definieer duidelijke operationele runbooks voor incidenten.
- Doorvoer en schaalbaarheid: behandel de hoofddoorvoer als alleen directioneel en benchmark uw hardware met een vaste DPI. Meet pagina's per uur, GPU-of CPU-gebruik en kosten, rightsize vervolgens batches en caching.
Mensen vragen ook
-
Wat is DeepSeek OCR en waarom is "optische compressie" belangrijk?
DeepSeek OCR comprimeert pagina-inhoud in compacte visuele tokens die de structuur behouden en het tokengebruik voor downstream-modellen verminderen. Dit is belangrijk omdat het een grotere documentdekking mogelijk maakt binnen vaste contextlimieten en de inferentiekosten verlaagt, terwijl tabellen, lijsten en lay-out intact blijven. -
Waar is de DeepSeek OCR GitHub-repo?
De officiële repository biedt code, voorbeelden en referenties voor het uitvoeren van lokale inferentie en het aanpassen van pijpleidingen. Kloon het om outputs te evalueren ten opzichte van uw basislijn OCR, aanpassen van prompts en exporteren van Markdown of JSON voor integratie. -
Is er een DeepSeek OCR API en is deze compatibel met OpenAI?
Er bestaat een API die OpenAI-stijl chatverzoeken met afbeeldingen of gerenderde PDF-pagina's accepteert. U kunt strikte JSON of Markdown aanvragen en vervolgens de responsinhoud parseren met behulp van standaardbibliotheken en workflows. -
Hoe gebruik ik het op PDF's?
Render elke PDF-pagina naar afbeeldingen met een consistente DPI, voer de vision OCR uit en verbind vervolgens pagina's en tabellen en lijsten na het proces. U kunt ook eerst classic OCR uitvoeren voor ruwe tekst en vervolgens DeepSeek toepassen voor lay-outsemantiek, structuurreparatie en markdown-generatie. -
Kan ik het lokaal met Ollama uitvoeren?
Community-instellingen koppelen DeepSeek-outputs aan lokale Ollama-modellen voor Q&A, extractie en validatie. Typische patronen omvatten streamlit-dashboards, watch‑folder-processors en lichtgewicht documentanalysators zonder te vertrouwen op externe cloudservices. -
Ik hoef alleen een gescande PDF te OCR met meertalige ondersteuning — wat is het gemakkelijkst?
Gebruik PDFelement voor een no-code workflow die deskew, denoise en meertalige OCR betrouwbaar afhandelt. Verbeter de scan, kies de juiste taal, bewijs met Read Aloud of AI Read, annoteer en exporteer een schone, doorzoekbare PDF.
 Veilige download
Veilige download