
PDFelement-Krachtige en eenvoudige PDF-editor
Ga aan de slag met de eenvoudigste manier om PDF's te beheren met PDFelement!
Python is een eenvoudig te gebruiken en efficiënte programmeertaal die vooral populair is bij tekst- en beeldverwerking. Omdat er een groot aantal bibliotheken beschikbaar is, kan Python automatisch verschillende soorten taken voor je uitvoeren, waaronder het extraheren van tekst uit afbeeldingen met behulp van OCR. Optical Character Recognition (OCR) is een technologie die gedrukte of handgeschreven tekens op afbeeldingen kan herkennen en de tekens kan extraheren.
Dit artikel beschrijft hoe je twee populaire OCR-engines kunt gebruiken om tekst uit afbeeldingen te extraheren in Python.
In dit artikel
Tekst uit afbeeldingen extraheren met Python
Extraheer tekst uit afbeeldingen in Python met behulp van Tesseract
Tesseract is een populaire open-source OCR-engine die voorgetraind om meer dan 100 talen te ondersteunen. In dit artikel gebruiken we Python-tesseract (pytesseract), een Python-wrapper voor Tesseract waarmee je Tesseract met Python kunt gebruiken. Alle stappen die in dit artikel worden beschreven, worden uitgevoerd op een Windows-pc.
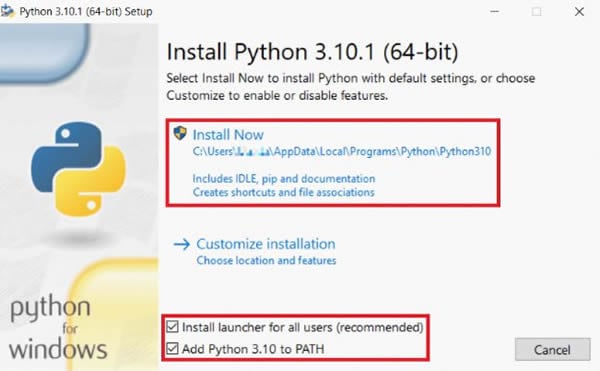
Stap 1 Download en installeer Python.
Python 3.6+ is vereist om pytesseract te gebruiken. Zorg er dus voor dat je een versie hoger dan 3.6 installeert. Selecteer vervolgens in het installatievenster Python X.XX toevoegen aan PATH om Python automatisch aan je systeempad toe te voegen. Anders moet je het systeempad handmatig configureren nadat je Python hebt geïnstalleerd.
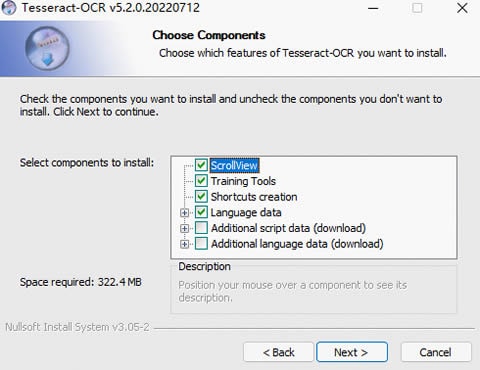
Stap 2 Download en installeer Tesseract.
Je kunt het nieuwste installatiepakket van Tesseract voor Windows downloaden. Selecteer vervolgens in het installatievenster de extra talen en scripts die je wilt installeren. Standaard kun je alleen de Engelse taal installeren.
Tesseract biedt een handig opdrachtregelprogramma waarmee je OCR op afbeeldingen kunt uitvoeren. Nadat je Tesseract hebt geïnstalleerd, open je een CLI-venster, navigeer je naar de map met het afbeeldingsbestand waarvan je de tekst wilt extraheren en voer je de volgende opdracht uit:
tesseract out
Deze opdracht extraheert tekst uit de opgegeven afbeelding en slaat de tekst op in het bestand out.txt. Om Tesseract met Python te gebruiken, ga je verder met de volgende stap om de vereiste Python-pakketten te installeren.
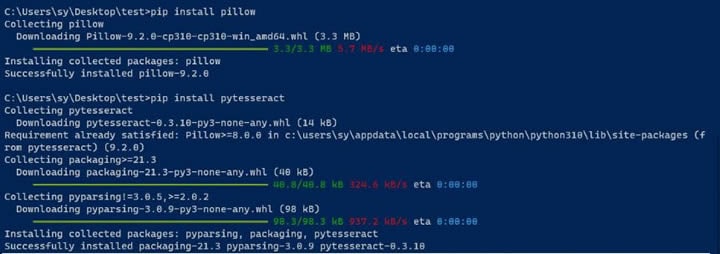
Stap 3 Installeer de Pillow- en pytesseract-pakketten.
Pillow wordt gebruikt om afbeeldingen te verwerken en pytesseract is vereist om Tesseract met Python te gebruiken. Je kunt de pakketten installeren door de volgende opdrachten uit te voeren in een CLI-venster:
pip install pillow
pip install pytesseract
Stap 4 Schrijf Python-code om tekst uit afbeeldingen te extraheren.
Nadat je de pakketten hebt geïnstalleerd, ben je nu klaar om je Python-code te schrijven om tekst uit afbeeldingen te extraheren. Ga naar de map waarin de afbeeldingsbestanden zijn opgeslagen waarvan je tekst wilt extraheren. Maak een tekstbestand en verander de naam in extract.py. Je kunt het tekstbestand naar elke gewenste naam wijzigen, maar zorg ervoor dat de bestandsnaamextensie py is.
Gebruik een teksteditor zoals Kladblok om het bestand extract.py te openen. Kopieer de volgende voorbeeldcode naar het bestand en sla het bestand op:
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string(Image.open('test.jpg')))
Om het voorgaande script succesvol uit te voeren, moet je een afbeeldingsbestand met de naam test.jpg in dezelfde map hebben als het bestand extract.py. In dit artikel wordt de volgende afbeelding als voorbeeld gebruikt.

Open een CLI-venster, ga naar de map waarin het afbeeldingsbestand zich bevindt en voer vervolgens de volgende opdracht uit:
python-extract.py
Je zou de volgende opdrachtuitvoer moeten krijgen.
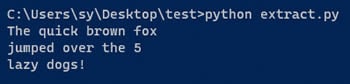
Uit de uitvoer blijkt dat de tekst met succes uit de afbeelding is geëxtraheerd. Hiermee is het basisproces van het gebruik van Tesseract met Python afgerond. Zie de documentatie ervan voor meer informatie over het gebruik van pytesseract.
Als je tekst uit meerdere afbeeldingen in een batch wilt extraheren, dan kun je op een eenvoudige manier de namen van de bestanden aan een TXT-bestand toevoegen, zoals images.txt. Bijvoorbeeld:
test.jpg
test1.jpg
Wijzig vervolgens het bestand extract.py als volgt:
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string('images.txt'))
Wanneer je het voorgaande script uitvoert, wordt de tekst geëxtraheerd uit alle afbeeldingen die zijn opgegeven in het bestand images.txt.
Extraheer tekst uit afbeeldingen in Python met EasyOCR
EasyOCR is een Python-pakket dat een kant-en-klare OCR-engine biedt en meer dan 80 talen ondersteunt. EasyOCR is eenvoudig te installeren en zeer eenvoudig te gebruiken. Dit maakt het een geweldige oplossing voor het uitvoeren van OCR met Python. Je hoeft alleen de PyTorch- (alleen vereist op Windows) en EasyOCR-pakketten te installeren, en dan kun je beginnen met het extraheren van tekst uit afbeeldingen met Python.
Stap 1 Installeer de vereiste Python-pakketten.
Om EasyOCR op Windows te gebruiken, moet je de PyTorch- en EasyOCR-pakketten installeren. Voer de volgende opdrachten achtereenvolgens uit om de pakketten te installeren:
pip install torch torchvision torchaudio
pip install easyocr
Stap 2 Schrijf Python-code om EasyOCR te gebruiken.
Ga naar de map waar je afbeelding zich bevindt, maak een .py-bestand, zoals extract.py, en kopieer vervolgens de volgende voorbeeldcode naar het bestand:
import easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext('test.jpg', detail = 0)
print(result)
De volgende afbeelding toont de opdrachtuitvoer wanneer je het bestand extract.py uitvoert.

Zoals weergegeven in de opdrachtuitvoer, wordt de tekst uit de testafbeelding geëxtraheerd.
Voor- en nadelen van het gebruik van Python
Python is een programmeertaal die gemakkelijk te leren en te gebruiken is. Het wordt veel gebruikt bij diep leren en natuurlijke taalverwerking. Vergeleken met andere talen is Python-code vaak eenvoudiger en korter. Het kost echter tijd om Python te leren, en je moet onderzoek doen naar de OCR-engines die je met Python wilt gebruiken.
Voordelen van het gebruik van Python om tekst uit afbeeldingen te extraheren:
- OCR-engines zoals Tesseract en EasyOCR zijn gratis te gebruiken.
- Python is geschikt voor batch- en repetitieve OCR-taken.
- Met Python kun je efficiënt en snel een groot aantal afbeeldingen verwerken.
- Je kunt degelijke conversieresultaten verkrijgen door de OCR-engine-opties aan te passen.
- Je kunt je goed ontworpen Python-script opslaan en gebruiken wanneer je tekst uit afbeeldingen wilt extraheren. Je kunt het script ook delen met anderen die dezelfde conversievereisten hebben.
Nadelen van het gebruik van Python om tekst uit afbeeldingen te extraheren:
- Python-kennis is vereist.
- Er moet onderzoek worden gedaan naar de OCR-engines die je wilt gebruiken.
- Open-source OCR-engines zijn mogelijk niet zo nauwkeurig als commerciële. Bovendien kunnen sommigen het handschrift misschien niet herkennen.
Toch is het altijd goed om iets nieuws te leren. Daarnaast kun je altijd overstappen naar andere tools wanneer dat nodig is. Er zijn tal van bestaande tools waarmee je snel tekst uit afbeeldingen kunt extraheren. Je kunt er een kiezen op basis van jouw vereisten.
Tekst uit afbeeldingen extraheren zonder Python
Als je geen fan bent van programmeren en op zoek bent naar een kant-en-klare tool, dan is PDFelement een snelle en gemakkelijke app die je zeker eens moet proberen.
PDFelement is een snelle en veelzijdige PDF-editor waarmee je PDF's kunt bekijken, bewerken en converteren. PDFelement is ook uitgerust met een geavanceerde OCR-engine, die kan worden gebruikt om tekst nauwkeurig en efficiënt uit afbeeldingen te extraheren.
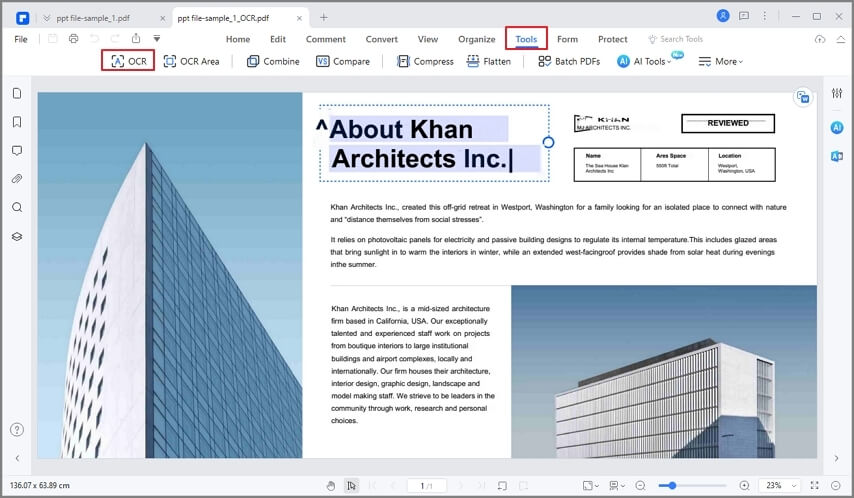
Je kunt deze stappen volgen om tekst uit afbeeldingen in PDFelement te extraheren:
Stap 1 Open PDFelement Sleep het afbeeldingsbestand waaruit je tekst wilt extraheren naar het PDFelement-venster. Je kunt ook PDF maken > Uit bestand kiezen en het afbeeldingsbestand selecteren. Vervolgens converteert PDFelement de afbeelding naar een PDF en opent deze in een nieuw tabblad.
Stap 2 Klik in het menu Extra op OCR om tekst uit de afbeelding te extraheren. Hierdoor kan PDFelement alle karakters in de afbeelding herkennen en deze omzetten in bewerkbare en doorzoekbare tekst.
Stap 3 Kopieer de tekst naar de gewenste locatie en bewerk de tekst. Je kunt de PDF met bewerkbare tekst ook converteren naar andere bestandsindelingen zoals Word of Excel.
Naast de OCR-engine biedt PDFelement ook andere functies die je kunnen helpen je productiviteit te verbeteren:
- Open en bekijk PDF-bestanden met hoge snelheid
- Bewerk inhoud in PDF-bestanden, zoals tekst en afbeeldingen
- Converteer PDF's naar verschillende bestandsindelingen zoals EPUB en Word
Conclusie
Python is een uitstekende programmeertaal die geschikt is voor het automatiseren van repetitieve taken. Door Python te gebruiken kun je eenvoudig en snel tekst uit afbeeldingen extraheren met open-source OCR-engines. Dit artikel biedt manieren om de OCR-mogelijkheden van Tesseract en EasyOCR aan te roepen met behulp van Python.
Het extraheren van tekst uit afbeeldingen met Python vereist echter programmeren, waarvoor basiskennis van programmeren en de Python-taal vereist is. Als je geen programmeerkennis hebt, bestaan er vele andere opties om tekstextractie uit afbeeldingen te voltooien. Een goede optie om te overwegen is PDFelement, een geavanceerde en geavanceerde applicatie waarmee je eenvoudig en efficiënt tekst uit afbeeldingen kunt extraheren.
