
Het gebruik van Linux Optical Character Recognition (OCR) software is een slimme zet voor mensen en bedrijven die enorme hoeveelheden gescande of PDF-documenten moeten coderen.
De software maakt het leven makkelijker als je papierloos wilt worden. Hiermee kun je je niet-bewerkbare bestanden "leesbaar" maken door je apparaat. Bovendien geeft het je de mogelijkheid om snel tekst uit je afbeeldingen te halen.
Er bestaan tonnen van dit soort toepassingen. Dit artikel is voor jou als je moeite hebt om te kiezen wat het beste is om tekst uit je afbeeldingen of PDF's te halen.
In dit artikel
Lijst van beste OCR-software
Het vinden van OCR-software voor Linux kan een uitdaging zijn. In tegenstelling tot Mac of Windows heeft dit besturingssysteem beperkte gebruikers, vaak in de tech-industrie. Door hun kleine aantal vind je minder apps van deze aard die voor dit systeem zijn ontwikkeld. Hier zijn er een paar.
Tesseract
Als je van gratis en open source software houdt, zou Tesseract een van je beste keuzes moeten zijn. Hoewel je geen cent nodig hebt om deze applicatie op je Linux te installeren, kan het je geweldige resultaten opleveren. Google heeft namelijk de motor voor deze app ontwikkeld en geleverd. Deze software kan de mogelijkheden en middelen van de techgigant enorm ten goede komen.

Tesseract is een krachtige letterherkenningstool. Het kan gemakkelijk delen van je boeken, PDF's, archieven en andere soorten teksten converteren. Het kan ook de tekens detecteren uit documenten met kleine lettergroottes en waar de tekst moeilijk te lezen is.
Tesseract kan zelfs de typen en maten van lettertypen herstellen volgens het origineel met minimale fout. Bovendien ondersteunt het meer dan 100 wereldwijde talen zoals Chinees, Spaans, Arabisch en regionale talen zoals Gujarati, Duitse Fraktur en Cebuano.
Om deze PDF OCR-software in Ubuntu te gebruiken, selecteer je het bestand dat je wilt verwerken.
Geef vervolgens na de opdrachtprompt van tesseract de informatie over het bestand, waaronder:
- De naam van het bestand dat je wil verwerken.
- De naam van het bestand dat je systeem zal maken om de geëxtraheerde tekst te bevatten - Het zal altijd worden opgeslagen als .txt, dus er is geen noodzaak om de bestandsextensie te verstrekken.
- Je kunt ook de --dpi-optie gebruiken om Tesseract op de hoogte te stellen van de resolutie van de afbeelding in de stippen per inch (dpi). Als je de dpi-waarde niet opgeeft, zal Tesseract het uitzoeken.
Als het bestand bijvoorbeeld img.png is, kan het commando er als volgt uitzien:
De uitvoer zal standaard img.txt zijn.
gImageReader
Een andere populaire OCR software in Linux is gImageReader. Deze toepassing kan veel functies uitvoeren, waaronder het extraheren van tekst uit meerdere bestanden en het controleren van spelling. Het kan ook post-verwerking uitvoeren op machinaal leesbare tekst.
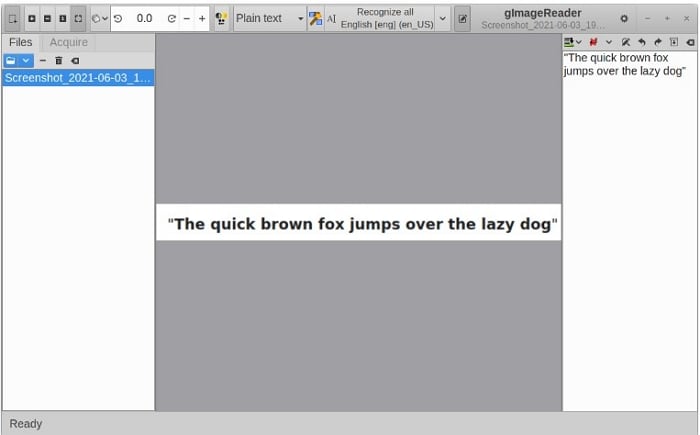
gImageReader kan zijn OCR-taak uitvoeren aan de hand van de volgende stappen:
Stap 1 Klik op Afbeeldingen toevoegen in het linkerdeel onder de werkbalk en selecteer de afbeelding of PDF die je wilt verwerken.
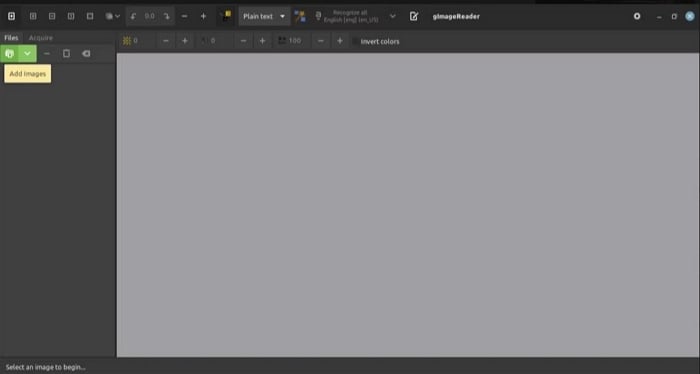
Stap 2 Klik op OK om de afbeelding of PDF naar de software te importeren.
Stap 3 Je kunt ook de optie hebben om tekst uit het bestand te extraheren dat op het scherm wordt weergegeven. Druk op de dropdown naast Afbeeldingen toevoegen en selecteer Screenshot maken. gImageReader maakt een screenshot van de inhoud op het scherm.
Stap 4 Zodra je de afbeelding hebt geladen naar gImageReader, klik je op het uitvoervenster Toggle (een met het pictogram notepad) om het uitvoerpaneel te openen. Door dit te doen, kan de tekst die je uit afbeeldingen of PDF's haalt, worden weergegeven.
Stap 5 Je hebt nu de mogelijkheid om de tekst in het bestand automatisch of handmatig te detecteren.
Stap 6 Als je kiest voor automatische identificatie, klik je op de lay-outknop Autodetect met alle tekstblokken in het geselecteerde document.
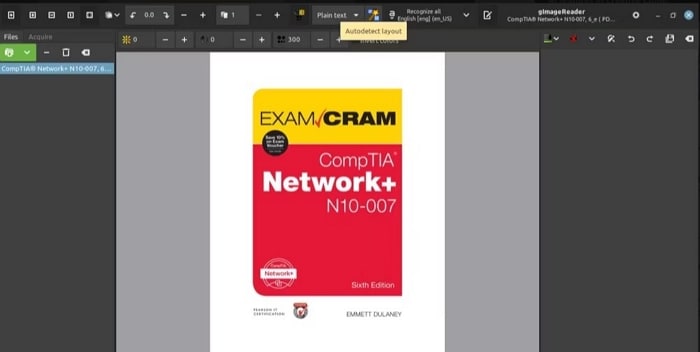
Stap 7 Selecteer Selectie herkennen > Huidige pagina om de tekstextractie te starten.
Stap 8 Als je de voorkeur geeft aan handmatige tekstselectie, plaatst je de muisaanwijzer boven de tekst die je wilt extraheren. Klik vervolgens op de knop Selectie herkennen om het proces te starten.
OCRFeeder
Een andere gratis en open-source OCR voor Linux is OCRFeeder. De ontwikkelaars wilden deze applicatie exclusief voor Linux-gebruikers. Op dit moment onderhoudt het GNOME-team deze software.
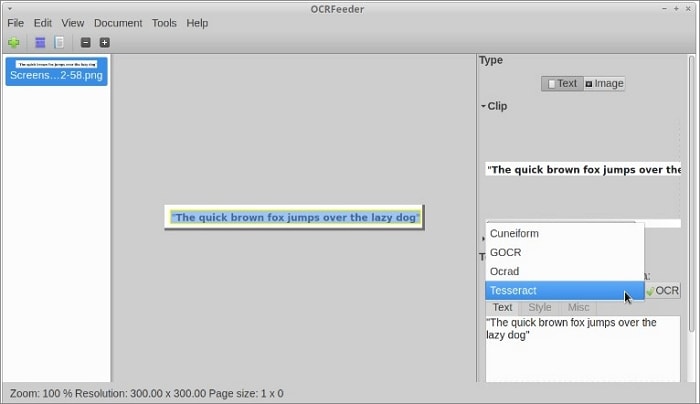
OCRFeeder zoekt naar inhoudsgebieden en omlijnt deze om het inhoudstype te detecteren, of het nu tekst of afbeelding is. Vervolgens verwerkt het tekstgebieden met behulp van de OCR-back-end.
Deze toepassing kan bijna alle command-line OCR-motoren, inclusief Tesseract, gebruiken om uit te voeren. Het heeft ook functies voor automatische detectie en automatische configuratie voor alle bekende gratis motoren. Volg deze procedure om OCRFeeder te gebruiken:
Stap 1 Open de software.
Stap 2 Importeer een afbeelding waarvan je de tekst wilt extraheren. Je kunt ook de map importeren met de bestanden die je van plan bent te verwerken.
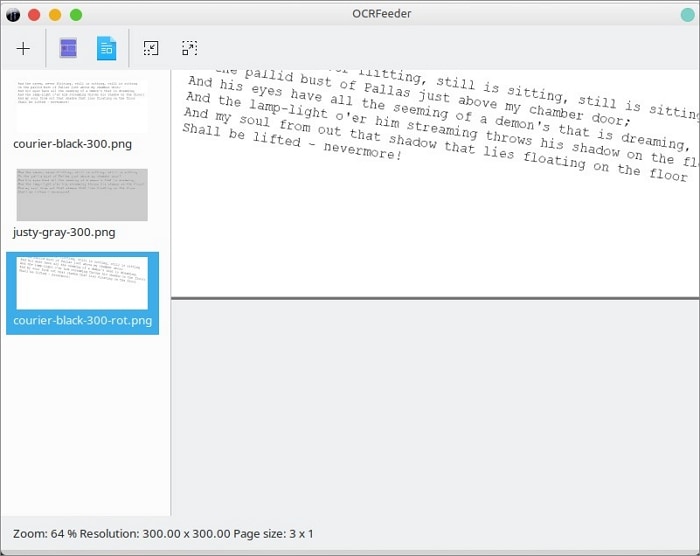
Stap 3 Druk op Identificeer document. Zodra je het document hebt geïdentificeerd, kun je handmatig de onderdelen selecteren die je wilt extraheren.
Stap 4 Voordat je het document exporteert, kies je Bewerken > Pagina bewerken om de gewenste pagina te selecteren.
Stap 5 Exporteer het document door te kiezen voor File > Export. Selecteer vervolgens het gewenste uitvoerformaat, bij voorkeur .txt-formaat.
FuzzyOCR
FuzzyOCR is een plug-in voor SpamAssassin, een anti-spamplatform dat verschillende afbeeldingsbestanden in e-mails inspecteert om te bepalen of ze spam zijn. Deze applicatie leest de afbeeldingen die aan de e-mail zijn gekoppeld. Het bepaalt vervolgens of ze spam zijn of niet op basis van een lijst met woorden.

Zodra deze OCR-software is geïnstalleerd en geconfigureerd, kan het zijn beelddetectie uitvoeren. Ontdek de procedure om te zien hoe deze applicatie werkt:
Stap 1 Na het downloaden, pak FuzzyOCR uit en verplaats de hele FuzzyOCR* bestanden en de FuzzyOCR directory.
Stap 2 Configureer het om het te laten werken met SpamAssassin door de bestandsnaam /etc/mail/spamassassin/FuzzyOCR.cf te openen en vervolgens enkele wijzigingen aan te brengen:

Stap 3 Zodra de FuzzyOCR is geconfigureerd, kun je elke e-mail aan SpamAssassin voeren om te zien of de plug-in correct aan de software is gekoppeld. Hier is een voorbeeld:
SpamAssassin kan nu beeldspam herkennen met FuzzyOCR
Voordelen en beperkingen van Linux OCR
Elke Linux OCR-software heeft veel voordelen. Dankzij de groei van de technologie zijn deze toepassingen steeds betrouwbaarder geworden. Het zijn must-haves voor mensen en bedrijven die snelle en nauwkeurige tekstextractie nodig hebben in de richting van een papierloos leven.
Voordelen
Hogere productiviteit - In plaats van jezelf te coderen of te delegeren aan iemand anders, kun je deze software uitvoeren en het zijn ding laten doen. Je kunt beginnen met het converteren van tekst terwijl je tegelijkertijd je gebruikelijke werk doet.
Lagere kosten - Deze technologie is goedkoper dan iemand betalen om een enorm stuk tekstgegevens handmatig in te voeren. PDF-tekst en afbeeldingen machinaal leesbaar maken kost minder energie en middelen.
Hoge nauwkeurigheid - Deze toepassingen maken het mogelijk om vastgelegde informatie leesbaar te maken. Flatbedscanners en de nieuwste digitale camera' s produceren beelden met een hoge resolutie, waardoor deze toepassingen tekst kunnen detecteren.
Verhoogde opslagruimte - Het opslaan van gescande afbeeldingsbestanden, vooral die met hoge resolutie, vereist aanzienlijke ruimte op je harde schijf. Het omzetten in machinaal bewerkbare documenten zou je schijf voldoende ruimte geven om andere, belangrijkere bestanden op te slaan.
Superieure gegevensbeveiliging - Verloren of gescande papieren documenten kunnen een beveiligingsnachtmerrie zijn. Een foute hantering van het bestand kan het vatbaar maken voor knoeien. Je kunt documenten opslaan zonder handtekeningen en zegels en converteren en opslaan in een bewerkbaar bestand.
Beperkingen
Moeite met het herkennen van handgeschreven tekst - Deze apps werken efficiënt met gedrukte tekst, maar hebben moeite met het lezen van handgeschreven tekst. Net als bij mensen zijn sommige handschriften moeilijk te lezen.
Mogelijk technische mensen nodig voor het installeren - Mogelijk heb je een paar mensen met geavanceerde technische vaardigheden nodig om Linux OCR-software voor PDF's en andere bestanden te installeren. In tegenstelling tot Windows of Mac weet slechts een klein deel van de mensen dit besturingssysteem te gebruiken.
Nog steeds tonnen bewerken - Hoewel de moderne OCR-software een hoge nauwkeurigheid heeft, zijn ze nog steeds vatbaar voor fouten. Je moet de documenten nog steeds zorgvuldig controleren en handmatig corrigeren om ervoor te zorgen dat ze foutloos zijn.
De herkenningsnauwkeurigheid is afhankelijk van de beeldkwaliteit.
Beste OCR-tool voor Windows, Mac en iOS
Applicaties voor het herkennen van letters zijn niet beperkt tot Linux gebruikers. Windows- en Mac-gebruikers kunnen ook kiezen uit een breed scala aan tekst-extractieve software. Onder de beschikbare software is PDFelement met zijn toonaangevende functies een intelligente keuze.
PDFelement heeft een volledig scala aan functies die tekstextractie een gebruiksvriendelijke ervaring maken. De software zal zijn taak nauwkeurig uitvoeren door PDF of andere afbeeldingsformaten te uploaden.
Naast OCR heeft het een schat aan functionaliteiten die je werk kunnen stroomlijnen. Nadat je de tekst bewerkbaar hebt gemaakt, kun je herzieningen uitvoeren en de bestanden converteren naar PDF, Word, Excel en PowerPoint. Je kunt er een eBook van maken door het te exporteren naar EPUB-formaat of een webpagina door er een HTML-bestand van te maken.
Hier zijn de stappen om deze software te installeren en te gebruiken als een OCR-tool op Windows:
Stap 1 Download en installeer PDFelement van de website.
Stap 2 Open een PDF-bestand en druk op de OCR op de secundaire navigatieknop om de OCR-functie te gebruiken. Er verschijnt een pop-upvenster met de vraag of je de extra functie wilt downloaden. Klik op Downloaden en voltooi de installatie.
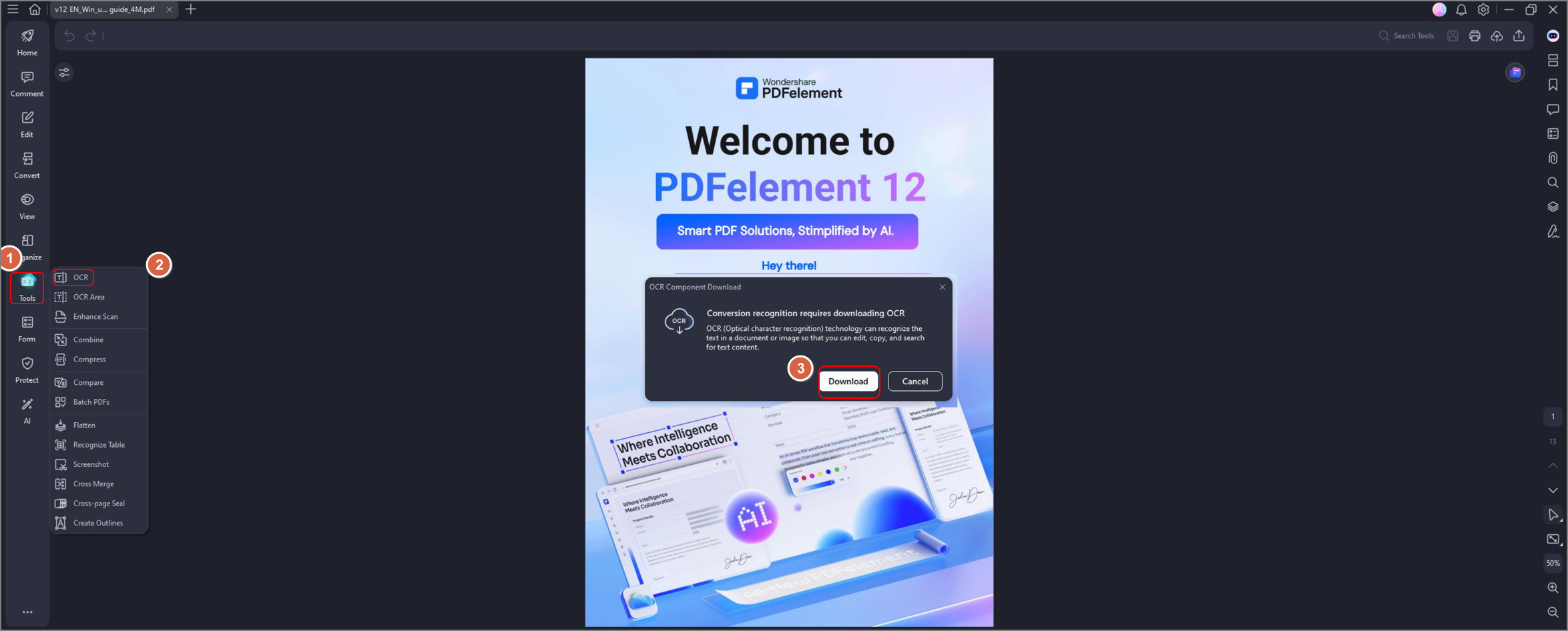
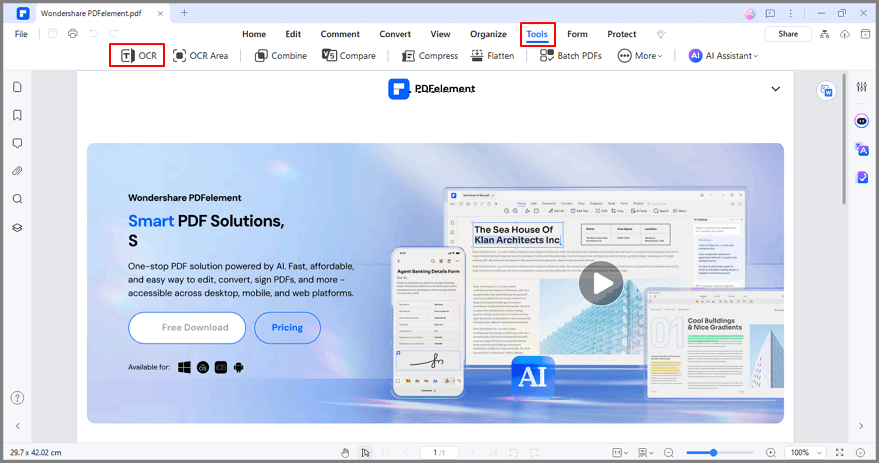
Stap 3 Zodra de installatie is voltooid, kun je het document omzetten in een tekstbestand. Klik op de OCR-knop, die je naar deze selectie zal leiden:
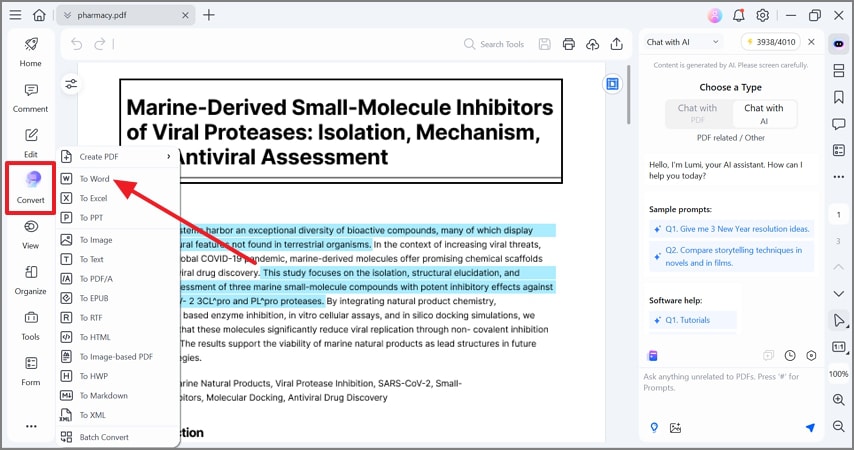
Stap 4 Nadat je de PDF-documentextractie hebt voltooid, kies je het formaat waarin je wilt dat je document wordt geconverteerd.
Als je de gratis proefversie gebruikt, kun je de OCR-functie gebruiken voor een beperkt aantal conversies en functionaliteiten. Misschien wil je betalen voor de Pro-versie om het meeste uit deze toepassing te halen.
Naast desktops kunnen mobiele gebruikers deze software ook op hun apparaten installeren. Gebruikers kunnen deze applicatie ook in de cloud gebruiken.
Conclusie
Voor mensen en bedrijven die vaak werken met documenten van welke vorm dan ook, zijn OCR' s voor PDF- en afbeeldingsbestanden essentieel voor een betere productiviteit. Met deze apps kun je de letters in je bestanden extraheren en ze omzetten in machinaal leesbare tekst. Als je hoogwaardige OCR-software wilt die gebruiksvriendelijk en robuust genoeg is voor je zware vereisten, is PDFelement je intelligente keuze.
