
In dagelijkse of zakelijke scenarios moet je mogelijk teksten scannen en overschrijven in bestanden, foto's, facturen en kwitanties. Optische karakterherkenning (OCR) API speelt een vitale rol bij het extraheren van tekst uit afbeeldingen en PDF's en het ontvangen van de gegevens in JSON, CSV, Excel of andere bestandsindelingen.
Dit artikel introduceert OCR API en drie populaire OCR API' s, waaronder Google Vision, Microsoft Computer Vision en Amazon Textract. Dit artikel presenteert ook PDFelement, een meer praktische OCR-oplossing.
In dit artikel
OCR API kan het kader van bestanden analyseren en de bestanden opsplitsen in blokken van tabellen of tekstregels. Vervolgens worden de lijnen onderverdeeld in één woord en tekens. Een bedrijf kan integraties met bestaande systemen bouwen met behulp van APIs. Dit kan helpen om aan specifieke zakelijke vereisten te voldoen en de tijd te verminderen die nodig is om werknemers op een nieuw platform te trainen.
Top 3 OCR API-tools
Google Vision
Google Vision is een cloud OCR service. Het kan handgeschreven inhoud, platte teksten en andere vormen van gegevens identificeren. Het kan ook informatie detecteren uit gescande documenten en afbeeldingen en stelt je in staat om OCR in de RPA-workflows te implementeren.
Google Vision is geen gebruiksklaar product. Voordat je Google Vision gebruikt, moet je ervoor zorgen dat je programmeervaardigheden en ervaring hebt met het omgaan met een behoorlijke hoeveelheid codering. Zorg ervoor dat je ook professionele kennis hebt in het toevoegen van gebruikersinterfaces voor het scannen en validatie van gegevens.
Er zijn verschillende oplossingen voor je om uit te kiezen. De prijzen zijn inclusief pay-per-use Cloud Vision API, het schalen van maandelijkse kosten en vaste tarieven per node-uur met gratis proeven voor AutoML Vision en AutoML Vision Edge. Je kunt een account aanmaken om de kosten te evalueren als je een beginner bent.
Microsoft Computer Vision
Microsoft Azure Computer Vision OCR is een AI-service die inhoud in afbeeldingen en video analyseert. Het kan een string en zijn informatie extraheren uit een aangegeven UI-element of een afbeelding.
De basisfuncties van Microsoft Computer Vision bevatten tekstextractie (OCR), beeldbegrip, ruimtelijke analyse en flexibele implementatie. Op basis van het inbedden van cloud vision-mogelijkheden in apps, kun je de vindbaarheid van inhoud, instant video-analyse en automatische data-extractie vergroten. Het kan ook worden gebruikt voor andere OCR-evenementen, zoals Klik OCR-tekst, Zweef over OCR-tekst, Dubbelklik op OCR-tekst, Krijg OCR -tekst en Vind OCR-tekstpositie.
De kosten van Microsoft Computer Vision zijn afhankelijk van de frequentie van transacties. De Computer Vision API is gratis als je slechts 5.000 transacties per maand gratis eist. Het zou echter duur zijn als je meer nodig hebt.
Amazon Textract
Amazon Textract is een dienst die automatisch inhoud, tekst en gegevens uit documenten kan extraheren. Naast een eenvoudige OCR-technologie kan het gegevens uit formulieren en tabellen herkennen. Met Textract hoeft de gebruiker alleen het bestand te uploaden, en binnen een korte tijd krijgt de gebruiker de tekst, tabel en formulieren in een gestructureerd bestand.
Textract OCR is gebaseerd op een deep-learning neuraal netwerk. Als iemand de gewonnen informatie (mens in de lus) verifieert, kan hij zich afstemmen op de gegevens en de nauwkeurigheid van de architectuur benutten. Het is echter niet volledig aanpasbaar of getraind op een aangepaste dataset.
Er zijn vier verschillende API' s in Amazon Textract: District Document Text API, Analyze Document API, Analyze Expense API en Analyze ID API. Het gratis pakket duurt slechts drie maanden en de details van elke maand zijn als volgt:
- Detect Document Text API: 1000 pagina's
- Analysze Document API; 100 pagina's per maand (form- of tabelfuncties) en 100 extra pagina's
- Analyze Expense API: 100 pagina's
- Analyze ID API: 100 pagina’s per maand
Gebruiksgevallen OCR API
OCR API’s zijn in veel gevallen belangrijk in de echte wereld. Hier zijn enkele voorbeelden:
Financiële diensten
De financiële sector, samen met het bankwezen, hechten veel belang aan OCR. Hier wordt het gebruikt om handschriftteksten van cheques, bankafschriften en winst- en verliesrekening te scannen en te herkennen. Er kan tijd worden bespaard bij het verwerken van lening- en hypotheekaanvragen.
Gezondheidszorg
OCR stelt ziekenhuizen en organisaties in staat om alle patiëntendossiers digitaal op te slaan. De vroegere ziekte, behandelingen en diagnostische tests zijn doorzoekbaar in een database. Daarnaast helpt het bij het extraheren van gegevens uit verzekeringstoepassingen om een betere service te bieden tussen patiënten en verzekeringsmaatschappijen.
Wettelijk
Er komt veel handschriftinhoud bij kijken in juridische scenarios. Deze sector kan verklaringen, affidavits, vonnissen, testamenten, deponeringen en andere gedrukte documenten digitaliseren met OCR-lezers. Bovendien maakt OCR het mogelijk om documenten uit de afgelopen miljoenen gevallen te zoeken en te vinden.
Beperkingen van OCR API's bij sommige gelegenheden
Hoewel OCR API' s praktisch zijn en in de meeste gevallen een nauwkeurige output bieden, hebben ze nog steeds enkele beperkingen. Ze zijn niet handig in de volgende situaties:
Gelijkaardige letter
Sommige OCR-software presteert slecht in het onderscheiden van letters die op elkaar lijken. Bijvoorbeeld, het herkennen van het verschil tussen het nummer 0 en de letter "O" is een uitdaging.
Handschrift-inhoud
Er kunnen grote verschillen zijn in ieders manier van schrijven. Als het woord niet duidelijk is geschreven, kan de OCR het niet identificeren.
Complexe taal
Veel OCR-software is goed in het extraheren van inhoud in het Engels. Als je echter een bestand uploadt in een taal met cursieve lettervariaties, zoals Arabisch, kan de uitvoer niet voldoende zijn naar jouw wens.
Word Font
Sommige OCR-APIs vinden het moeilijk om te kleine of te grote letters over te schrijven.
Beste OCR-software voor computers en smartphones
In vergelijking met de bovengenoemde professionele tools, als je op zoek bent naar een gebruiksvriendelijke software om tekst uit documenten te halen, is PDFelement je beste keuze. Het biedt een intuïtieve interface en vraagt om een soepele gebruikerservaring. Hoewel je geen ervaring hebt met het gebruik van OCR, kun je de eerste keer met succes tekst uit het bestand halen.
PDFelement biedt je een verscheidenheid aan functies. Hiermee kun je alle bewerkingen of wijzigingen in PDF maken op deze enkele toepassing. Met betrekking tot OCR kun je het bestand gratis converteren vanuit een afbeelding of een gescande PDF. Na conversie kun je elk formaat gebruiken dat je wilt exporteren.
PDFelement OCR ondersteunt veel veelgebruikte talen, zoals Engels, Duits, Frans, Italiaans, Portugees, Spaans, Roemeens, Turks, Russisch, Pools, Tsjechisch, Nederlands, Hongaars, Thais, Vietnamees, Zweeds, Maleis en Indonesisch. De uitvoer van tekst in deze talen wordt duizenden keren getest om ervoor te zorgen dat het je een nauwkeurig en nauwkeurig resultaat geeft.
Wat nog belangrijker is, PDFelement is ontworpen om verschillende situaties te ondersteunen. Je kunt het downloaden als een individuele toepassing op de computer en telefoon. Bovendien past het zich aan zowel het Windows-systeem als macOS aan. In offline modus is de alleen tekstherkenning om tekst uit gescande documenten te halen nog steeds beschikbaar.
Als je een heel groot document wilt bewerken, is PDFelement ook de beste keuze. Met behulp van de software kun je een PDF OCR' en met een maximum van 100 pagina's. Bovendien kun je OCR op maximaal 10 bestanden tegelijkertijd verwerken. De Batch PDF hieronder is ontworpen zodat je meerdere documenten kunt verwerken.
Stappen voor het gebruik van PDFelement OCR op iOS-apparaten
Om een bestand met PDFelement OCR te converteren, voer je de volgende stappen uit: selecteer OCR, selecteer een taal en download de uitvoer. Het volgende cijfer toont een voorbeeld van het gebruik van PDFelement voor iOS om een bestand via OCR op iPhone te converteren.
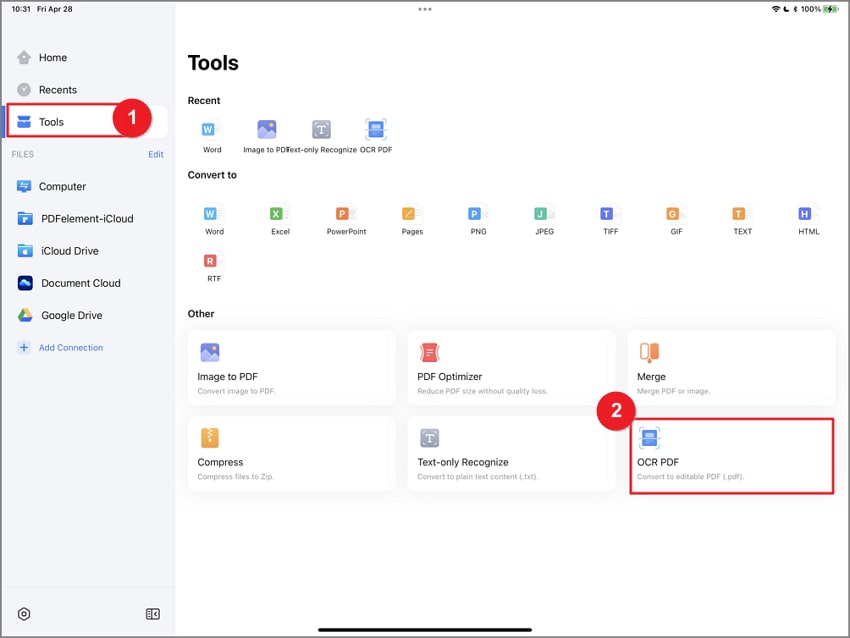
Stap 1 Upload het bestand
Start de PDFelement-applicatie op je iPhone. Op de startpagina vind je Tools en tik je op OCR PDF. Selecteer het bestand om een nieuwe taak te starten zoals gevraagd.
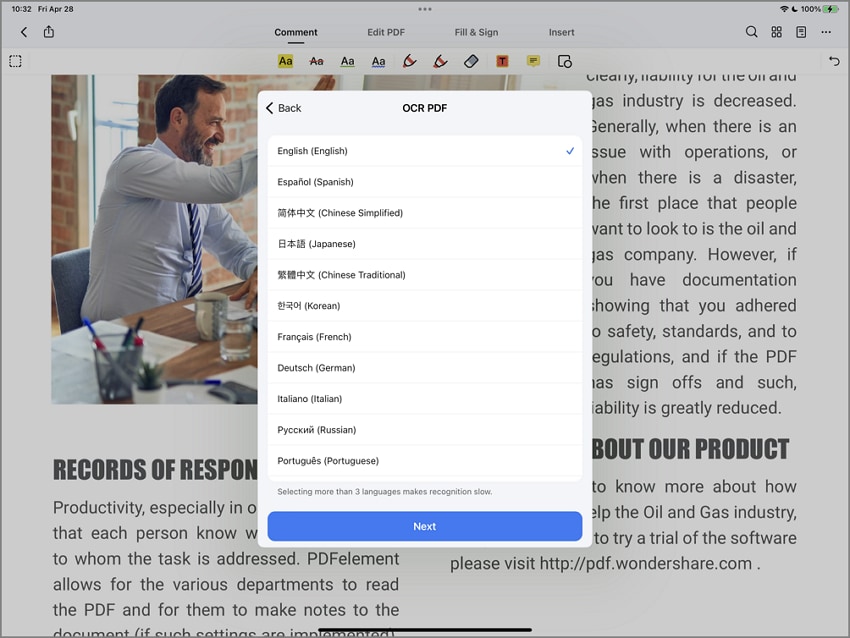
Stap 2 Selecteer een taal
Je kunt een teksttaal selecteren zoals vermeld op de pagina. Je kunt maximaal drie talen tegelijk selecteren. Tik vervolgens op Volgende om het document te verwerken.
Stap 3 Bewaar of bewerk het bestand
Je kunt de herkende tekst na ongeveer een paar seconden verkrijgen. Je kunt het bestand wijzigen met behulp van verschillende tools die door de toepassing worden geleverd, of je kunt het bestand rechtstreeks opslaan.
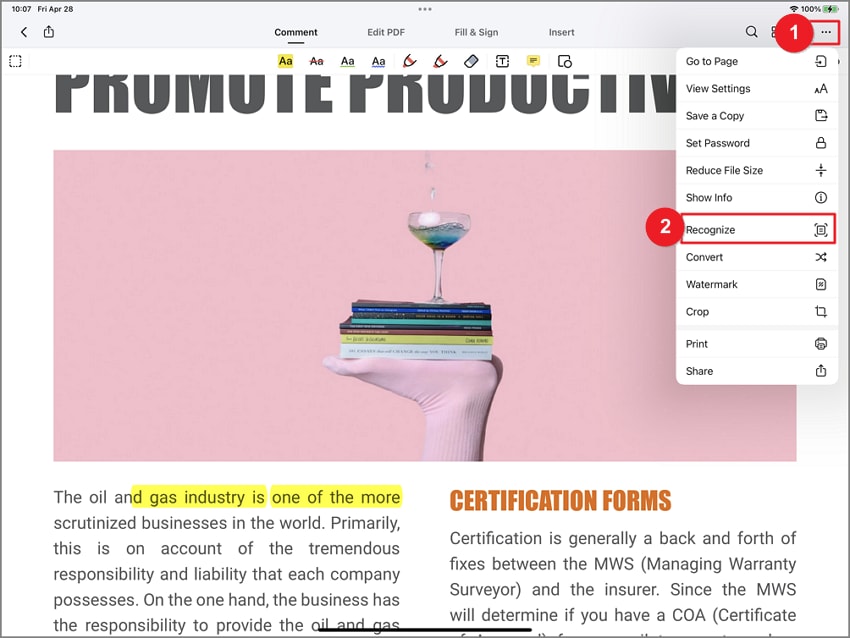
Opmerking: Als alternatief, als je een bestand in PDFelement hebt geopend, kun je het pictogram in de rechterbovenhoek van de bewerkingsinterface selecteren. Tik vervolgens op Recognize [Herkennen] om te beginnen.
Conclusie
Google Vision, Microsoft Computer Vision en Amazon Textract zijn de top 3 API' s voor OCR die je voor verschillende scenarios kunt gebruiken. API' s zijn echter complexer en vereisen hoge kosten.
PDFelement is ontworpen om aan je dagelijkse gebruikseisen te voldoen. Je kunt PDFelement gebruiken om teksten uit documenten in verschillende formaten efficiënt te over te schrijven. Download PDFelement nu en geniet van een soepele ervaring wanneer je PDF's op je telefoon of computer bewerkt.
