
PDFelement-Krachtige en eenvoudige PDF-editor
Ga aan de slag met de eenvoudigste manier om PDF's te beheren met PDFelement!
Met optische tekenherkenning (OCR) kun je een gescand document omzetten in een bewerkbaar en doorzoekbaar tekstbestand. Het heeft verschillende toepassingen en kan onder andere worden bereikt door gebruik te maken van open source-tools.
Het verkrijgen van een open source is een redelijke optie voor mensen die de OCR willen aanpassen aan hun vereisten. Als je een uitstekende OCR Open Source-tool wilt hebben, dan hebben wij de oplossing voor jou. In dit artikel ontdek je de beste tools om OCR online uit te voeren en waarom mensen deze nodig hebben. Laten we beginnen!

In dit artikel
Waarom hebben mensen een open source OCR-tool nodig?
Enkele van de redenen waarom mensen open source OCR-tools nodig hebben zijn:
- Wanneer je OCR wilt aanpassen aan je vereisten, dan heb je een open-source OCR nodig.
- Doordatopen-source OCR flexibeler en makkelijker aan te passen is dan de OCR-tools kan het je beter van dienst zijn als je later iets innovatiefs aan het programma wilt toevoegen.
- Omdat voor de meeste OCR-software extra kosten nodig zijn, en je wilt geen abonnement kopen als je de software één of twee keer per maand nodig hebt. In dit scenario wil je mogelijk over open source OCR-software beschikken.
Top 4 beste open source OCR-tools in 2022
Omdat je nu weet waarom je open source OCR-software nodig hebt, ben je wellicht op zoek naar de beste optie. Dat vind je in deze rubriek. Hier hebben we de beste tools voor OCR PDF open source-tools beoordeeld, waaronder:
1. Tesseract OCR
Tesseract van Hewlett-Packard wordt algemeen beschouwd als de beste open-source OCR-engine. Het is open source-software die is uitgebracht onder de Apache-licentie en sinds 2006 door Google wordt gesteund. De Tesseract OCR-engine is ook een van de meest nauwkeurige en breed toegankelijke open-sourceoplossingen. De nieuwste stabiele versie van Tesseract, 4.1.1, is gebaseerd op LSTM en kan tekst in maximaal 116 talen verwerken.
Omdat het wordt uitgevoerd vanaf de opdrachtregel (CIL), heeft Tesseract geen grafische gebruikersinterface (GUI). Met zijn geavanceerde voorverwerkingspijplijn voor afbeeldingen en leermogelijkheden voor neurale netwerken kan het nieuwe kennis verwerven. Bovendien spelen taal, beeldkwaliteit, datatraining, paginasegmentatie en engine allemaal een rol in hoe nauwkeurig het resultaat is.
Afbeeldingen kunnen worden voorbewerkt met bibliotheken zoals OpenCV en ImageMagick om ruis te elimineren, het formaat te wijzigen, te binariseren, te roteren, om te keren, uit te zetten en te eroderen voor nauwkeurigere resultaten bij het gebruik van deze open source OCR-pythontool.
Belangrijkste kenmerken
- Het werkt met veel talen en heeft wrappers voor veel daarvan, waaronder Java, Python, Ruby en Swift.
- Het is compatibel met andere programma's voor het maken van GUI's.
- Om afbeeldingen te laden, raadpleegt de engine de open source OCR-bibliotheek, zoals Leptonica.
- Het biedt veel mogelijkheden voor mensen om betrokken te raken bij hun gemeenschap.
- Talen die het ondersteunt: 116 talen, waaronder Engels, Spaans, Hindi, Pools, Portugees en andere.
Voordelen
Ondersteunt meerdere programmeertalen
Betere nauwkeurigheid dan concurrenten
Nadelen
Moeilijk te begrijpen voor een beginneling
Volg de onderstaande stappen om opensource PDF OCR uit te voeren met Tesseract OCR:
Stap 1 Download eerst het nieuwste installatieprogramma voor Tesseract. Open de opdrachtprompt en schrijf 'pip install pytesseract' om het te installeren.
Stap 2 Nu moet je de afbeelding lezen. Ga naar Google Colab en schrijf de volgende code: Opmerking: In cmd=r moet je het pad van tesseract.exe op je computer opgeven. In cv2.imread moet je de naam opgeven van de afbeelding die je naar Colab hebt geüpload.

Stap 3 Nadat je de afbeelding hebt gelezen, is het tijd om de afbeeldingstekst naar een tekenreeks te converteren. Daarvoor moet je het volgende stuk code toevoegen:

Stap 4 Wanneer je de code uitvoert, krijg je de afbeeldingstekst als uitvoer.
2. Azure-OCR
De Azure OCR API in de cloud geeft programmeurs toegang tot geavanceerde algoritmen voor het lezen van tekst die gestructureerde gegevens uit gescande foto's opleveren. Met de OCR-tools van Microsoft Azure kun je gedrukte typoscript in verschillende talen, handgeschreven tekst in vele talen en valutasymbolen uit afbeeldingen, cijfers en PDF-brochures met meerdere pagina's extraheren.
De Azure Cognitive Service, Computer Vision, is een kunstmatige intelligentie (AI)-service die stilstaande en bewegende beelden evalueert op relevante informatie. Een van de vele functies die Azure OCR biedt, is toegang tot Azure Cognitive Services, een computervisie-API.
Talen die het ondersteunt: 10+ talen, waaronder Engels, Japans, Spaans, enz.
Belangrijkste kenmerken
- Er zijn drie cloudservices beschikbaar en je kunt vergelijken hoe goed hun OCR-algoritmen werken.
- Hierdoor kunnen ontwikkelaars eenvoudig vooraf gebouwde AI-functionaliteit aan hun software toevoegen.
- Vanwege de draagbaarheid van containers kun je dezelfde rijke API's gebruiken die toegankelijk zijn in Azure.
- Informatie in verschillende talen en scripts, gedrukt en handgeschreven, kan worden opgehaald.
Voordelen
Op AI gebaseerde scripts voor OCR
Juiste nauwkeurigheid
Nadelen
Moeilijk voor regulieregebruikers
Volg de onderstaande stappen om OCR uit te voeren met Azure OCR:
Stap 1 Bezoek de Azure Portal in de browser van je voorkeur. Om toegang te krijgen tot Cognitive Services ga je naar de sectie AI + Machine Learning onder Alle services in het hoofdmenu.
Stap 2 Kies Computer Vision, Maken en stel het formulier in.
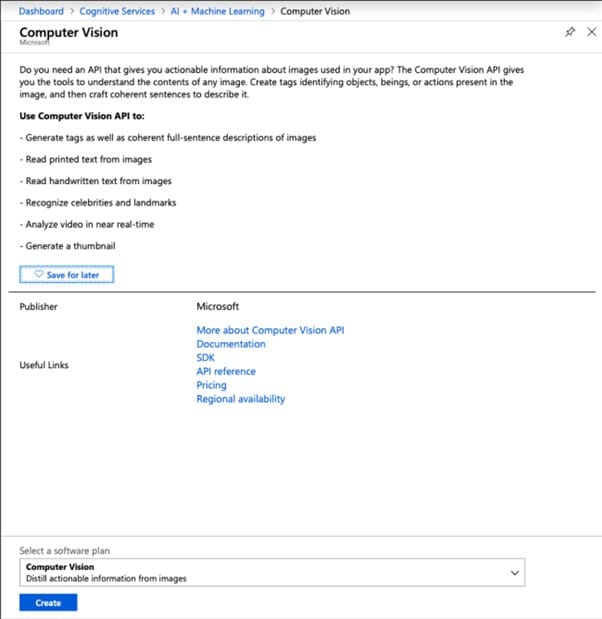
Stap 3 Om toegang te krijgen tot de OCR-Test-bron, ga je naar het Dashboard. Om toegang te krijgen tot Keys, kies je deze in het submenu Resource Management.
Stap 4 Er zullen twee sleutels zichtbaar zijn; kopieer KEY 1. Schrijf de volgende code in Google Colab.
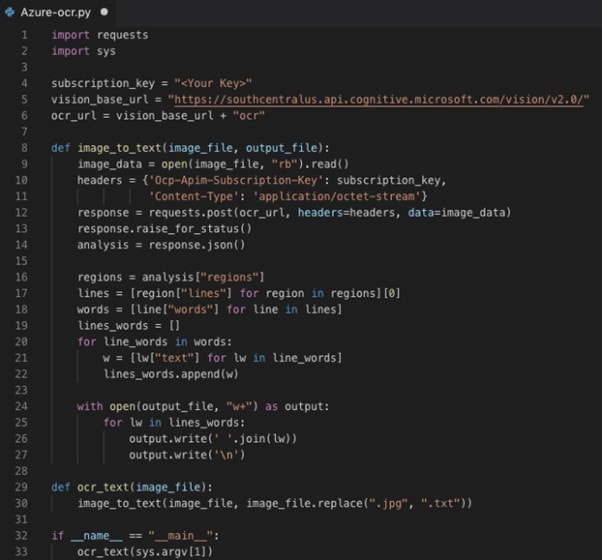
Stap 5 De code zal, wanneer deze wordt uitgevoerd, tekstuele uitvoer op de console leveren, wat de tekst zal zijn die uit de afbeelding wordt gehaald.
3. Abbyy-OCR
Wanneer je een afgedrukte of handgeschreven pagina scant naar ABBYY OCR, dan kun je deze converteren naar een bewerkbare documentkopie. Het heeft een taaldetectiecapaciteit van meer dan 200 talen. Met behulp van dit programma kun je PDF-/afbeeldingsbestanden converteren naar Word-, Excel-, PDF-, enz., doorzoekbare tekstindelingen. Herkende informatie wordt omgezet in XML (Extensible Markup Language). Deze bron is een Java-, .NET-, iOS- en Python-bibliotheek.
Je kunt documenten annoteren en markeren, beveiligingsmaatregelen toevoegen, zoals wachtwoorden en digitale handtekeningen, documenten hiermee verifiëren, en meer. De tijdbesparende functies van de app maken het makkelijker om samen aan projecten te werken.
Talen die het ondersteunt: Werkt met 200 talen, waaronder Russisch, Hebreeuws, Chinees, Farsi en andere.
Belangrijkste kenmerken
- Compatibel met verschillende talen, waaronder Japans, Koreaans, Arabisch, Farsi, Vietnamees en Thais.
- Je kunt je documenten exporteren naar Word, Excel of PowerPoint.
- Plaats het resulterende archief in een cloudopslagservice zoals Google Drive.
- De gebruikersinterface is strak en intuïtief, waardoor het eenvoudig is om wijzigingen aan te brengen en bestanden te ordenen.
Voordelen
Snel en vlug
Gemakkelijke samenwerking
Nadelen
Behoorlijk duur
4.OCR-Space
Als je gescande foto's of PDF's wilt omzetten in bewerkbare documenten, dan hoef je niet verder te gaan dan OCR Space. Het is een gratis webgebaseerde OCR-tool die vier verschillende OCR-engines gebruikt om tekst uit foto's en pdf's te halen en deze in een overlay weer te geven. OCR Space is een gebruiksvriendelijke onlinetool voor het omzetten van gescande documenten en PDF's in bewerkbare tekst die digitaal kan worden doorzocht.
Om een document naar bewerkbare bestanden te converteren, kun je het bestand uploaden of de URL plakken. Het programma kan bepalen wanneer een foto vergroot moet worden en doet dit automatisch.
Talen die het ondersteunt: 20+ talen, waaronder Engels, Hindi, Russisch, Spaans, enz.
Belangrijkste kenmerken
- Scan snel documenten, inclusief ingewikkelde tafelindelingen, zoals bonnen.
- Je kunt ontdekken hoe een afbeelding is georiënteerd en deze automatisch draaien als deze verkeerd staat.
- Het ondersteunt bestanden met slecht contrasterende tekst tegen een ingewikkelde achtergrond.
- Maximaliseer de OCR-nauwkeurigheid door afbeeldingsbestanden of documentinhoud automatisch te vergroten.
Voordelen
Volledig online
Inloggen is niet nodig
Nadelen
Kan geen uitvoer genereren naar een Word-document
Volg de onderstaande stap om OCR uit te voeren met OCR Space:
Stap 1 Ga naar OCR Space en selecteer een afbeelding of PDF op je computer door op de knop Bestand kiezen te klikken. Afbeeldingen in PNG-, JPG- en WebP-indelingen worden allemaal ondersteund door OCR Space. Je kunt ook de URL van de afbeelding of het bronbestand van de PDF invoeren of plakken.
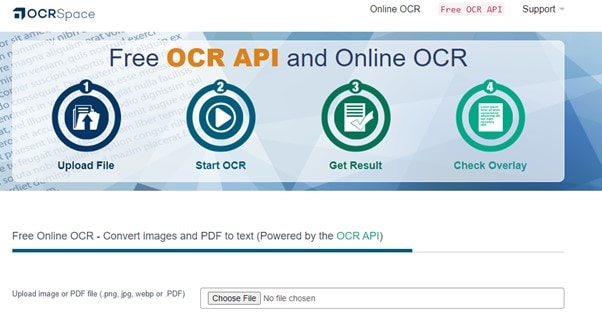
Stap 2 Klik op het tabblad Taal om de taal in te stellen op basis van de tekst in de afbeelding of pdf. Je hebt drie keuzes in OCR Space waaruit je kunt kiezen voordat je met het OCR-proces begint. Selecteer de opties op basis van je vereisten.
Stap 3 Wanneer je de zoekmachines hebt gekozen naast de optie Selecteer OCR-engine om te gebruiken, dan klik je op OCR starten om het scanproces te starten.
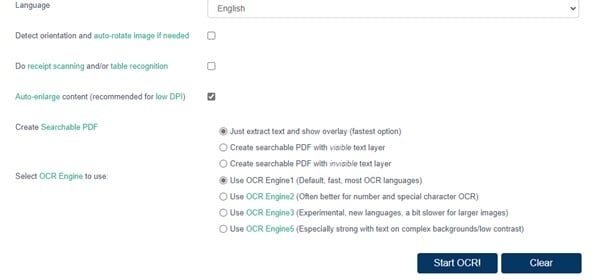
Stap 4 Nadat het proces is voltooid krijg je een uitvoer in tekstvorm naast de afbeelding of pdf. Je kunt wijzigingen aanbrengen, Downloaden kiezen of kopiëren en in een teksteditor plakken.
Beste tool voor PDF OCR's op Windows en iOS
Wilt je de beste tool voor PDF OCR voor Windows- en iOS-apparaten vinden? Je vindt het in deze sectie. Hoewel de bovenstaande tools het beste zijn voor open-source OCR, kunnen ze in geen enkele situatie PDF's bewerken. Daarvoor heb je kwaliteitssoftware nodig, zoals PDFelement.
PDF is geschikt voor het afhandelen van alle PDF-aanvragen. Gebruikers kunnen gescande documenten eenvoudig bewerken en profiteren van de mogelijkheid om OCR-herkende teksten te converteren naar veelgebruikte formaten, waaronder Microsoft Word, Excel, HTML en PowerPoint. Aanpasbare tekstvelden, stempels en opmerkingen maken ook deel uit van de tool. Met deze tool is het maken van content als team een fluitje van een cent.
Belangrijkste kenmerken
- Afbeeldingen en gescande documenten met tekst erin kunnen worden herkend.
- Hiermee kunnen gebruikers tekst uit een gescande PDF of afbeelding extraheren en deze voor andere doeleinden gebruiken, zoals kopiëren of zoeken.
- Met snelle verwerkingstijden en uitgebreide bewerkingstools kun je een PDF maken die opvalt.
- Dankzij de gebruiksvriendelijke interface kunnen zelfs beginners snel aan de slag.
Wat we leuk vinden
Gemakkelijk om tekst in PDF te zoeken
Kan het OCR-resultaat converteren naar een Word-indeling
De juiste maatwerktool
Wat we niet leuk vinden
Sommige bewerkingsfuncties kun je niet gratis gebruiken
Prijzen: Gratis tot $ 7,99
Talen die het ondersteunt: Het ondersteunt tot wel 29 verschillende talen.
Om PDF OCR uit te voeren via PDFelement, volg je de onderstaande stappen:
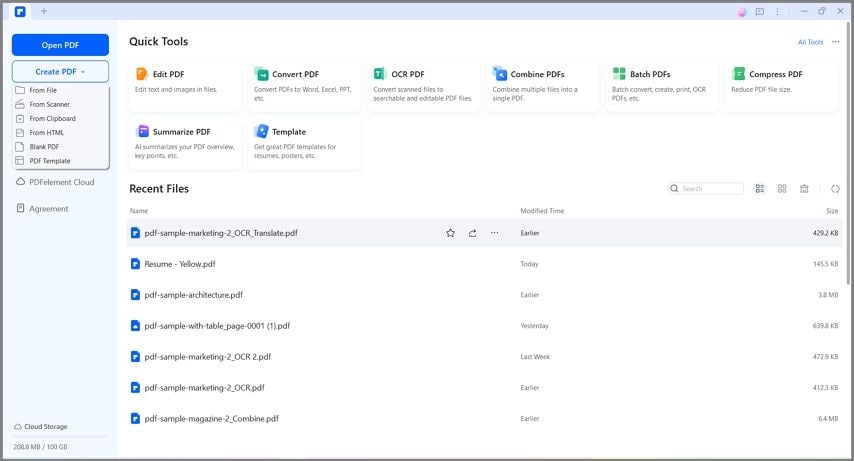
Stap 1 Download PDFelement op je apparaat en start het. Klik op het +-pictogram of sleep je PDF om deze te uploaden.
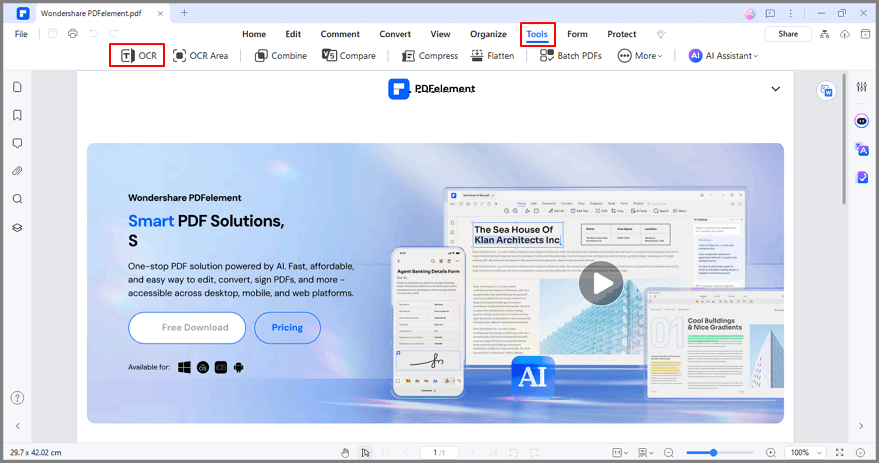
Stap 2 Klik op Tool en vervolgens op OCR om door te gaan. Er verschijnt een venster; selecteer Bewerkbare tekst en selecteer vervolgens de taal door op Taal kiezen te klikken. Klik vervolgens op OK om de scan te starten.
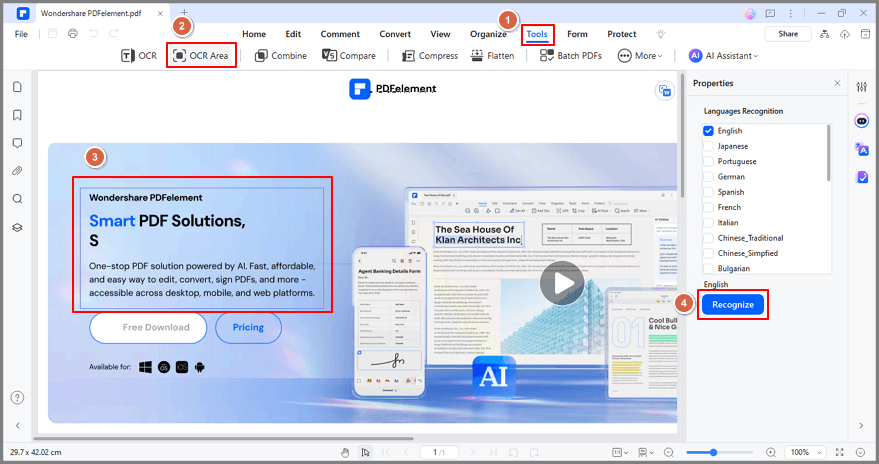
Stap 3 Na de scan kun je op Bewerken klikken om de PDF-tekst te bewerken of op Naar tekst om de bewerkbare tekst naar je computer te exporteren.
Conclusie
Met open-source OCR-tools kunnen mensen eenvoudig tekst uit afbeeldingen en pdf's extraheren zonder de software te downloaden. Het stelt de gebruiker ook in staat de tool aan te passen volgens zijn vereisten. Met de OCR Open Source-tools die in dit artikel worden besproken, hopen we dat je de juiste hebt gevonden. Bovendien, als je PDF OCR op een Windows- of iOS-apparaat wilt doen, dan is onze topaanbeveling PDFelement.
